publications
My research interests lie at the intersection of robotics, computer vision, and machine learning, including sensing and perception, localization and navigation, multiagent systems, human-robot interaction, 3D computer vision, neural rendering (NeRF and 3DGS), self-supervised learning, foundation models (VFMs, VLMs, MLLMs), generative models, adversarial learning, uncertainty quantification, and dataset and benchmark. My works have been published in top-tier venues such as CVPR, ICCV, ECCV, NeurIPS, RSS, CoRL, ICRA, IROS, and RA-L with multiple first-author papers selected for spotlight, highlight, and oral presentations.
2025
- Preprint
 MemoGaussian: 4D Gaussian Splatting with Spatial MemoryYiming Li, Zitai Xu, Xiangyu Han, and 7 more authorsUnder Review, 2025
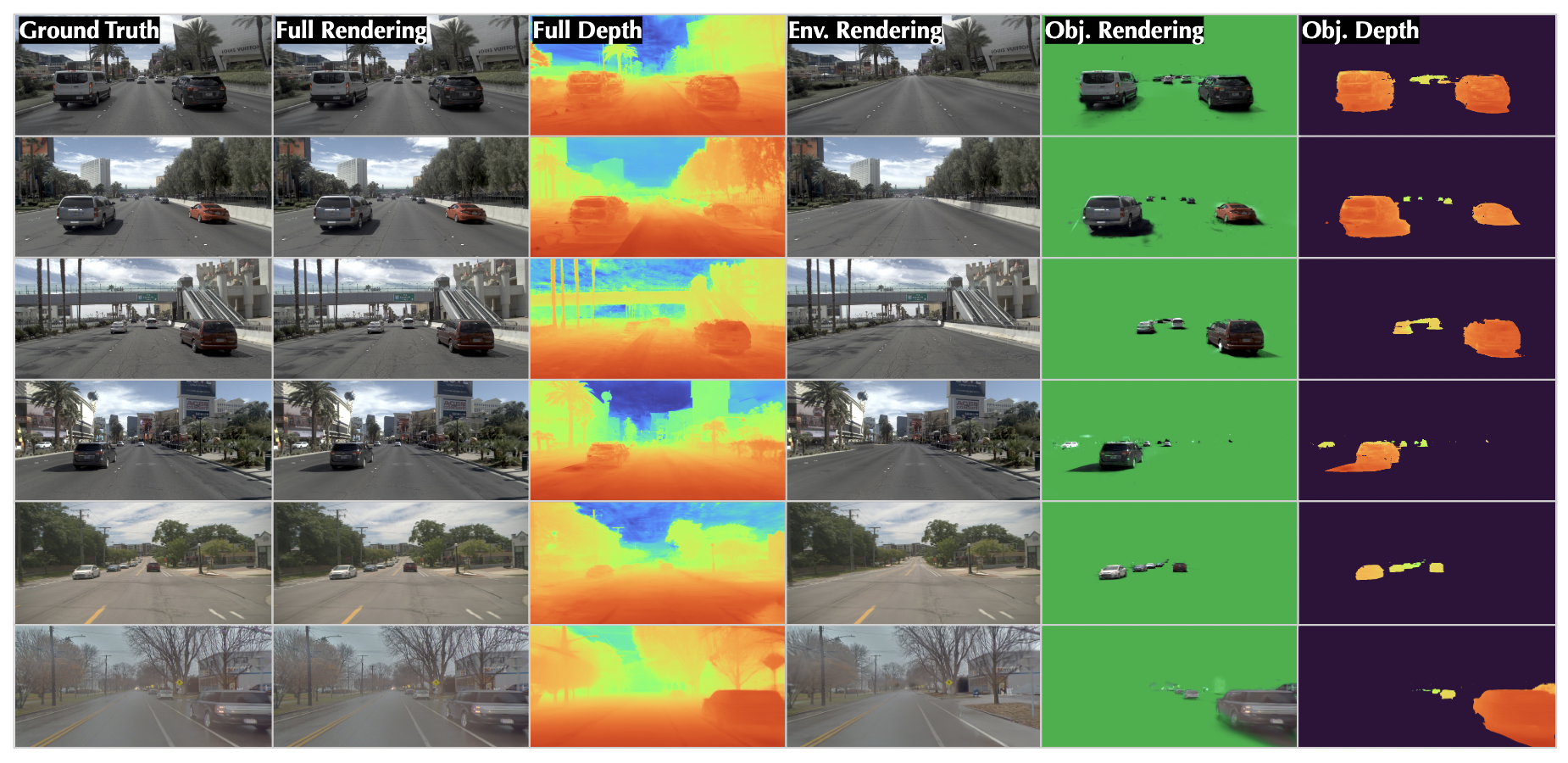
MemoGaussian: 4D Gaussian Splatting with Spatial MemoryYiming Li, Zitai Xu, Xiangyu Han, and 7 more authorsUnder Review, 2025Humans naturally develop spatial memory when navigating new environments to recall relevant information upon revisiting the same place. We aim to equip autonomous agents with similar cognitive skills, by investigating a challenging urban scene reconstruction problem under long-term temporal changes. To model the complex and dynamic urban scene, we introduce MemoGaussian, a memory-augmented framework to learn composite representations of temporally changing urban scenes with self-supervision. Grounded in Gaussian Splatting, MemoGaussian simultaneously captures scene geometry and appearance while stratifying scenes into environment and object fields. The environment field represents permanent structures in the 3D scene, such as buildings and roads, while the object field captures transient entities like moving or static pedestrians and vehicles. Given an RGB video, along with the environment field built using the past traversal RGB videos, MemoGaussian can simultaneously adapt the environment field and discover novel objects appearing in the current traversal. This environmental adaptation and object discovery emerge by jointly optimizing the environment and object fields over the 2D image space. To the best of our knowledge, MemoGaussian is the first method to achieve self-supervised spatiotemporal decomposition of permanent and transient components within the scene, enhancing object segmentation and sensor simulation without human annotations.
- Preprint
 Diffusion Transformer as Scalable Imitating DriverYicheng Liu, Baijun Ye, Tianyuan Yuan, and 2 more authorsUnder Review, 2025
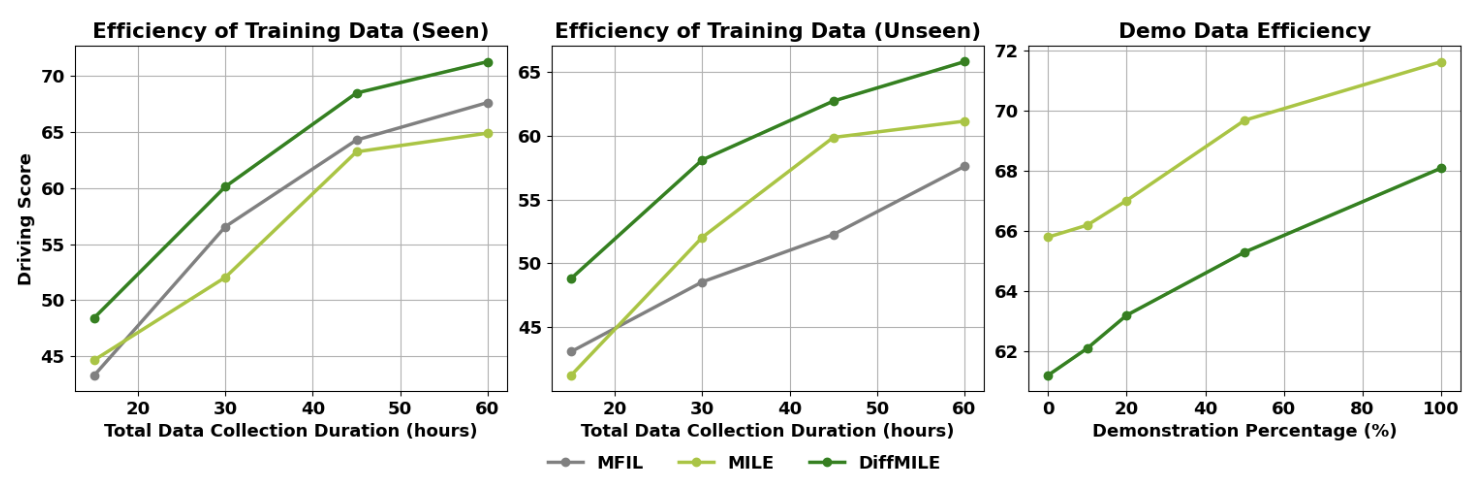
Diffusion Transformer as Scalable Imitating DriverYicheng Liu, Baijun Ye, Tianyuan Yuan, and 2 more authorsUnder Review, 2025Imitation learning (IL) has become a popular approach for autonomous driving, leveraging large expert datasets to learn driving policies. However, scaling IL to handle high-capacity architectures, complex observations, and multimodal driving actions remains challenging. To address these issues, we propose DiffMILE, a diffusion model-based imitation learning framework that integrates an autoregressive world model with diffusion transformer decoders for actions and observations within a model-based imitation learning framework. By introducing a novel hybrid conditioning method, DiffMILE achieves improved scalability, training stability, and expressiveness. Experimental results show that DiffMILE efficiently utilizes data, excels in urban driving scenarios, and demonstrates strong generalization to unseen towns and weather conditions, while also adapting effectively to few-shot demonstration settings.
- Preprint
 Splat-Sim: A Closed-Loop Driving Simulator with Gaussian SplattingJunhao Ge, Zuhong Liu, Longteng Fan, and 5 more authorsUnder Review, 2025
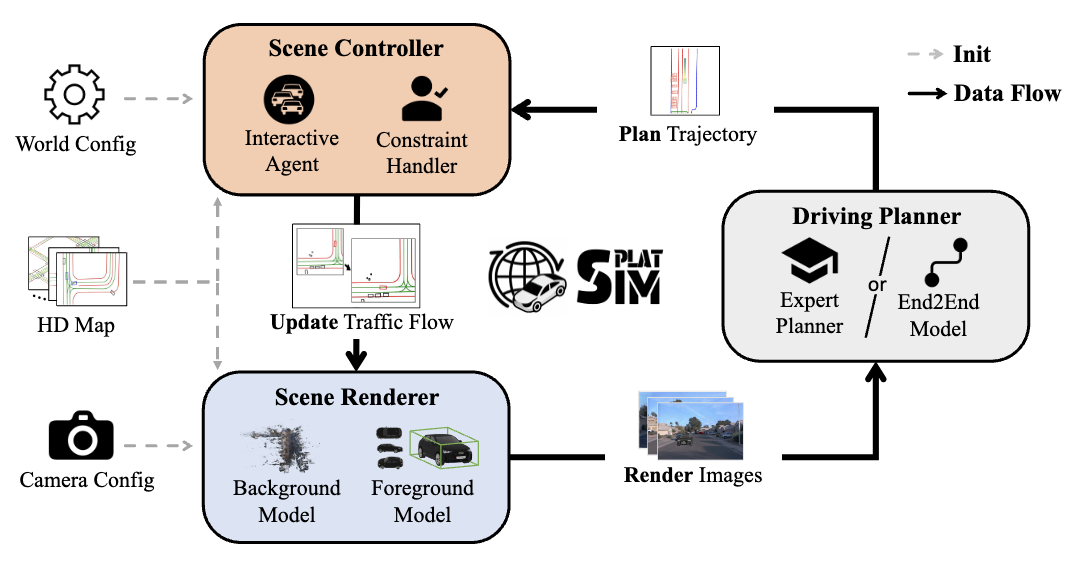
Splat-Sim: A Closed-Loop Driving Simulator with Gaussian SplattingJunhao Ge, Zuhong Liu, Longteng Fan, and 5 more authorsUnder Review, 2025We introduce Splat-Sim, a simulation framework with Gaussian Splatting for testing autonomous driving (AD) systems, tailored for sensor-realistic closed-loop evaluation in scenarios involving dynamic agent interactions. Splat-Sim generates agent vehicles that interact with ego vehicle in configurable scenarios. We reconstruct scene backgrounds, integrating agent vehicles from a pre-trained 3D Gaussian Splatting (3DGS) vehicle library. Our framework renders images from the perspective of ego vehicle, dynamically adjusting the agent vehicles to produce novel viewpoint images in real time. In our experiments, we generate additional data via our platform to train end-to-end models (E2E models), validating the quality of the synthetic data and the effectiveness of our closed-loop simulation. Our findings indicate that open-loop evaluations of E2E models do not fully reflect performance limitations and reveal the need for improved generalization across real-world datasets. Our platform demonstrates the potential to fuse and extend real-world datasets, offering a robust simulator for AD model development and testing.



2024
- Preprint
 Extrapolated Urban View Synthesis BenchmarkXiangyu Han, Zhen Jia, Boyi Li, and 8 more authorsTechnical Report, 2024
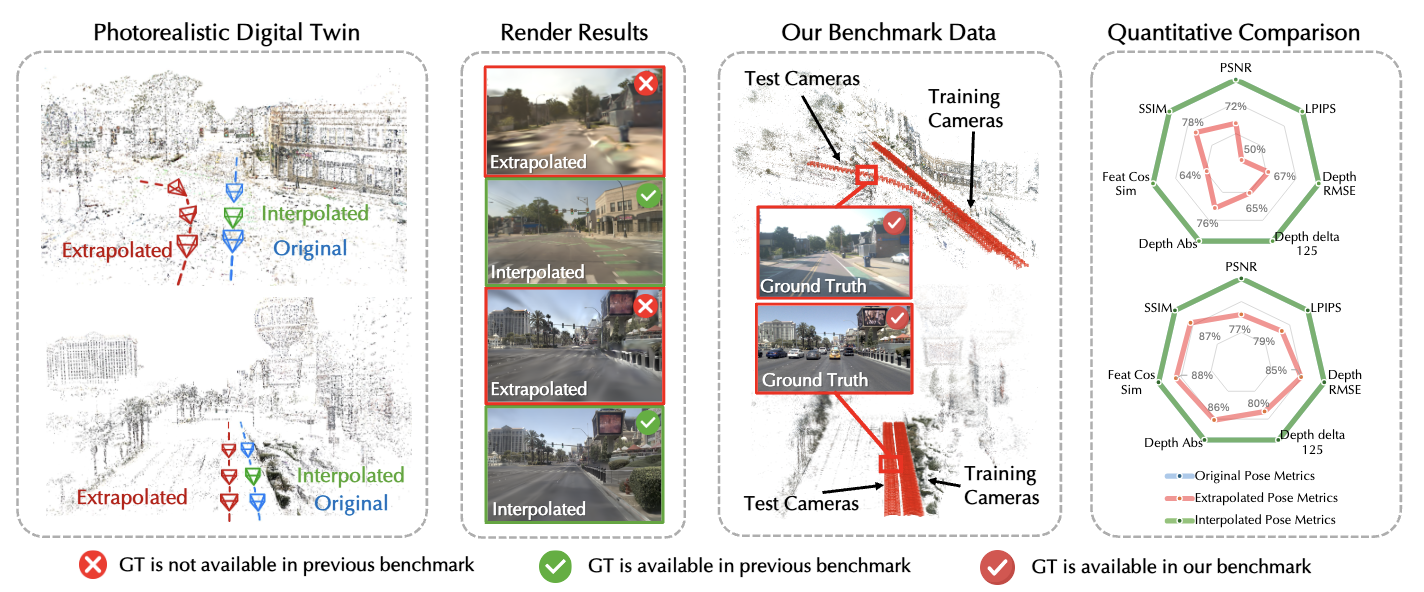
Extrapolated Urban View Synthesis BenchmarkXiangyu Han, Zhen Jia, Boyi Li, and 8 more authorsTechnical Report, 2024Photorealistic simulators are essential for the training and evaluation of vision-centric autonomous vehicles (AVs). At their core is Novel View Synthesis (NVS), a crucial capability that generates diverse unseen viewpoints to accommodate the broad and continuous pose distribution of AVs. Recent advances in radiance fields, such as 3D Gaussian Splatting, achieve photorealistic rendering at real-time speeds and have been widely used in modeling large-scale driving scenes. However, their performance is commonly evaluated using an interpolated setup with highly correlated training and test views. In contrast, extrapolation, where test views largely deviate from training views, remains underexplored, limiting progress in generalizable simulation technology. To address this gap, we leverage publicly available AV datasets with multiple traversals, multiple vehicles, and multiple cameras to build the first Extrapolated Urban View Synthesis (EUVS) benchmark. Meanwhile, we conduct quantitative and qualitative evaluations of state-of-the-art Gaussian Splatting methods across different difficulty levels. Our results show that Gaussian Splatting is prone to overfitting to training views. In addition, incorporating diffusion priors and improving geometry cannot fundamentally improve NVS under large view changes, highlighting the need for more robust approaches. We will release our resources for the community to advance simulation technology for self-driving and urban robotics.
- Preprint
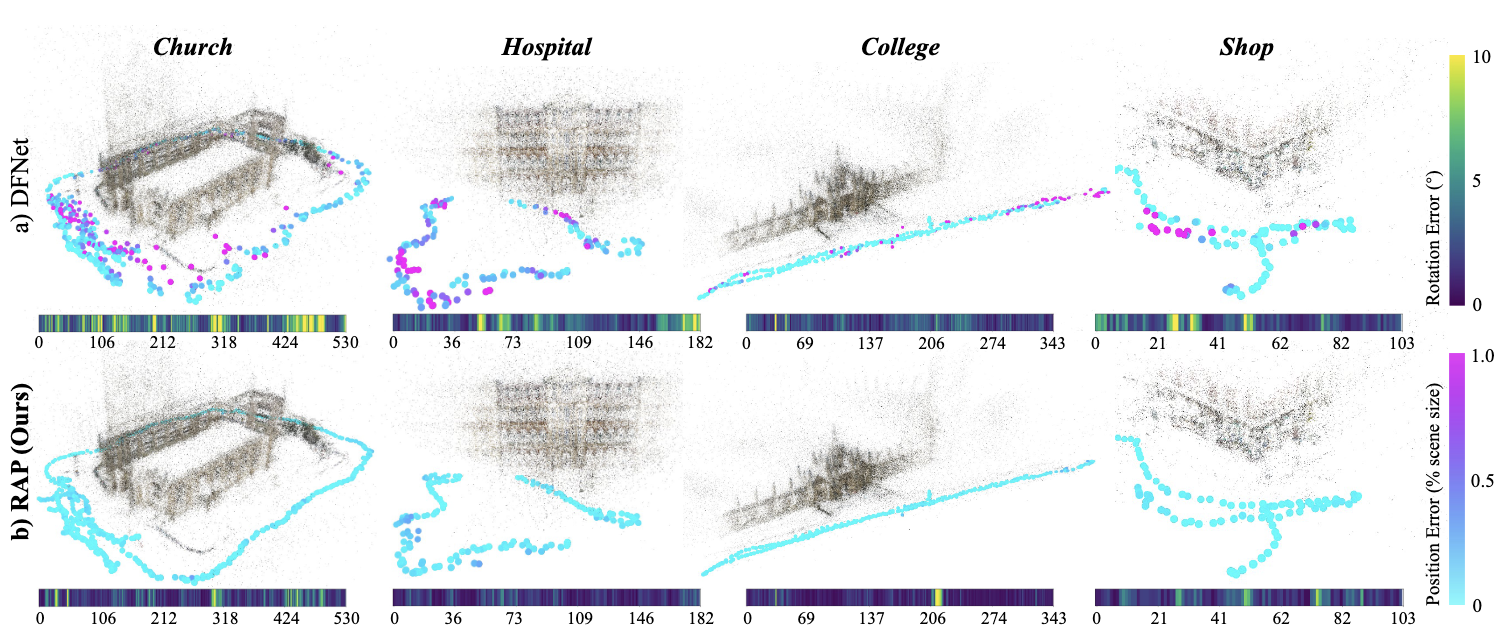 Unleashing the Power of Data Synthesis in Visual LocalizationSihang Li, Siqi Tan, Bowen Chang, and 3 more authorsTechnical Report, 2024
Unleashing the Power of Data Synthesis in Visual LocalizationSihang Li, Siqi Tan, Bowen Chang, and 3 more authorsTechnical Report, 2024Visual localization, which estimates a camera’s pose within a known scene, is a long-standing challenge in vision and robotics. Recent end-to-end methods that directly regress camera poses from query images have gained attention for fast inference. However, existing methods often struggle to generalize to unseen views. In this work, we aim to unleash the power of data synthesis to promote the generalizability of pose regression. Specifically, we lift real 2D images into 3D Gaussian Splats with varying appearance and deblurring abilities, which are then used as a data engine to synthesize more posed images. To fully leverage the synthetic data, we build a two-branch joint training pipeline, with an adversarial discriminator to bridge the syn-to-real gap. Experiments on established benchmarks show that our method outperforms state-of-the-art end-to-end approaches, reducing translation and rotation errors by 50% and 21.6% on indoor datasets, and 35.56% and 38.7% on outdoor datasets. We also validate the effectiveness of our method in dynamic driving scenarios under varying weather conditions. Notably, as data synthesis scales up, the ability to interpolate and extrapolate training data for localizing unseen views emerges.
- NeurIPS Spotlight
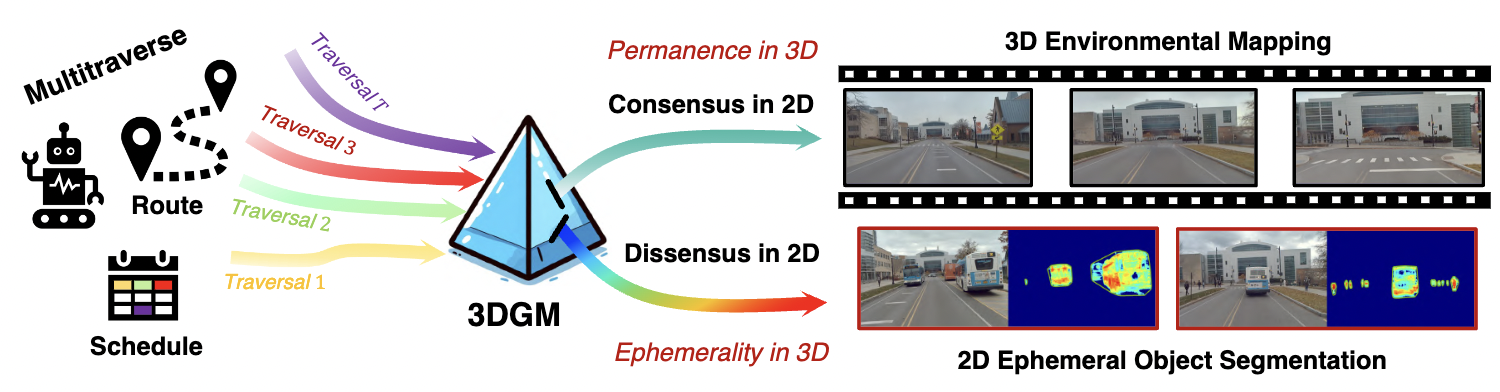 Memorize What Matters: Emergent Scene Decomposition from MultitraverseYiming Li, Zehong Wang, Yue Wang, and 5 more authorsIn Advances in Neural Information Processing Systems, 2024
Memorize What Matters: Emergent Scene Decomposition from MultitraverseYiming Li, Zehong Wang, Yue Wang, and 5 more authorsIn Advances in Neural Information Processing Systems, 2024Humans naturally retain memories of permanent elements, while ephemeral moments often slip through the cracks of memory. This selective retention is crucial for robotic perception, localization, and mapping. To endow robots with this capability, we introduce 3D Gaussian Mapping (3DGM), a self-supervised, camera-only offline mapping framework grounded in 3D Gaussian Splatting. 3DGM converts multitraverse RGB videos from the same region into a Gaussian-based environmental map while concurrently performing 2D ephemeral object segmentation. Our key observation is that the environment remains consistent across traversals, while objects frequently change. This allows us to exploit self-supervision from repeated traversals to achieve environment-object decomposition. More specifically, 3DGM formulates multitraverse environmental mapping as a robust representation learning problem, treating pixels of the environment and objects as inliers and outliers, respectively. Using robust feature distillation, feature residuals mining, and robust optimization, 3DGM jointly performs 3D mapping and 2D segmentation without human intervention. We build the Mapverse benchmark, sourced from the Ithaca365 and nuPlan datasets, to evaluate our method in unsupervised 2D segmentation, 3D reconstruction, and neural rendering. Extensive results verify the effectiveness and potential of our method for self-driving and robotics.
- NeurIPS
 RadarOcc: Robust 3D Occupancy Prediction with 4D Imaging RadarFangqiang Ding, Xiangyu Wen, Yunzhou Zhu, and 2 more authorsIn Advances in Neural Information Processing Systems, 2024
RadarOcc: Robust 3D Occupancy Prediction with 4D Imaging RadarFangqiang Ding, Xiangyu Wen, Yunzhou Zhu, and 2 more authorsIn Advances in Neural Information Processing Systems, 20243D occupancy-based perception pipeline has significantly advanced autonomous driving by capturing detailed scene descriptions and demonstrating strong generalizability across various object categories and shapes. Current methods predominantly rely on LiDAR or camera inputs for 3D occupancy prediction. These methods are susceptible to adverse weather conditions, limiting the all-weather deployment of self-driving cars. To improve perception robustness, we leverage the recent advances in automotive radars and introduce a novel approach that utilizes 4D imaging radar sensors for 3D occupancy prediction. Our method, RadarOcc, circumvents the limitations of sparse radar point clouds by directly processing the 4D radar tensor, thus preserving essential scene details. RadarOcc innovatively addresses the challenges associated with the voluminous and noisy 4D radar data by employing Doppler bins descriptors, sidelobe-aware spatial sparsification, and range-wise self-attention mechanisms. To minimize the interpolation errors associated with direct coordinate transformations, we also devise a spherical-based feature encoding followed by spherical-to-Cartesian feature aggregation. We benchmark various baseline methods based on distinct modalities on the public K-Radar dataset. The results demonstrate RadarOcc’s state-of-the-art performance in radar-based 3D occupancy prediction and promising results even when compared with LiDAR- or camera-based methods. Additionally, we present qualitative evidence of the superior performance of 4D radar in adverse weather conditions and explore the impact of key pipeline components through ablation studies.
- ECCV
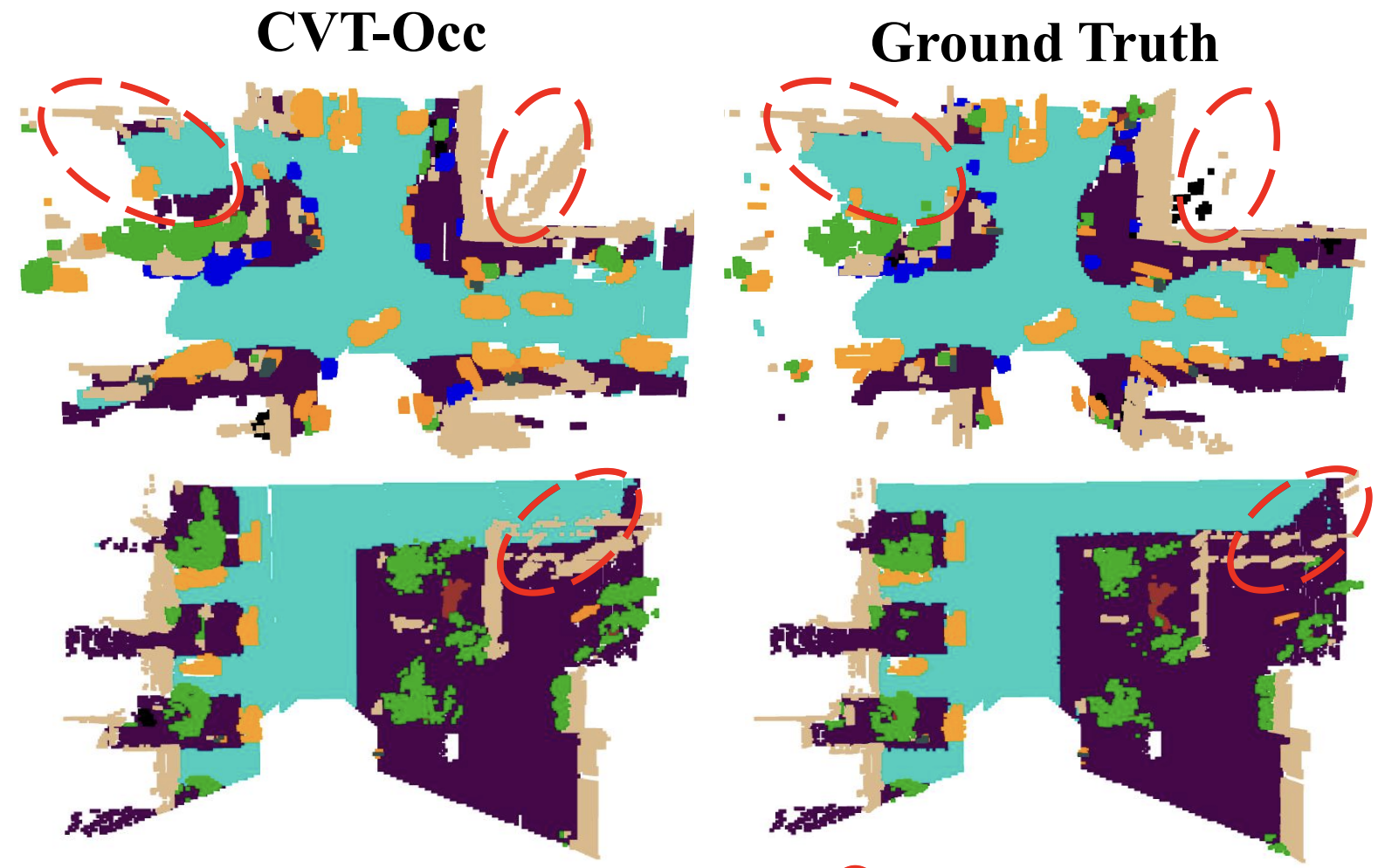 CVT-Occ: Cost Volume Temporal Fusion for 3D Occupancy PredictionZhangchen Ye, Tao Jiang, Chenfeng Xu, and 2 more authorsIn European Conference on Computer Vision, 2024
CVT-Occ: Cost Volume Temporal Fusion for 3D Occupancy PredictionZhangchen Ye, Tao Jiang, Chenfeng Xu, and 2 more authorsIn European Conference on Computer Vision, 2024Vision-based 3D occupancy prediction is significantly challenged by the inherent limitations of monocular vision in depth estimation. This paper introduces CVT-Occ, a novel approach that leverages temporal fusion through the geometric correspondence of voxels over time to improve the accuracy of 3D occupancy predictions. By sampling points along the line of sight of each voxel and integrating the features of these points from historical frames, we construct a cost volume feature map that refines current volume features for improved prediction outcomes. Our method takes advantage of parallax cues from historical observations and employs a data-driven approach to learn the cost volume. We validate the effectiveness of CVT-Occ through rigorous experiments on the Occ3D-Waymo dataset, where it outperforms state-of-the-art methods in 3D occupancy prediction with minimal additional computational cost.
- IROS
 SSCBench: A Large-Scale 3D Semantic Scene Completion Benchmark for Autonomous DrivingYiming Li, Sihang Li, Xinhao Liu, and 8 more authorsIn IEEE/RSJ International Conference on Intelligent Robots and Systems, 2024
SSCBench: A Large-Scale 3D Semantic Scene Completion Benchmark for Autonomous DrivingYiming Li, Sihang Li, Xinhao Liu, and 8 more authorsIn IEEE/RSJ International Conference on Intelligent Robots and Systems, 2024Semantic scene completion (SSC) is crucial for holistic 3D scene understanding by jointly estimating semantics and geometry from sparse observations. However, progress in SSC, particularly in autonomous driving scenarios, is hindered by the scarcity of high-quality datasets. To overcome this challenge, we introduce SSCBench, a comprehensive benchmark that integrates scenes from widely-used automotive datasets (e.g., KITTI-360, nuScenes, and Waymo). SSCBench follows an established setup and format in the community, facilitating the easy exploration of the camera- and LiDAR-based SSC across various real-world scenarios. We present quantitative and qualitative evaluations of state-of-the-art algorithms on SSCBench and commit to continuously incorporating novel automotive datasets and SSC algorithms to drive further advancements in this field.
- IROS
 Lidar-based 4d occupancy completion and forecastingXinhao Liu, Moonjun Gong, Qi Fang, and 4 more authorsIn IEEE/RSJ International Conference on Intelligent Robots and Systems, 2024
Lidar-based 4d occupancy completion and forecastingXinhao Liu, Moonjun Gong, Qi Fang, and 4 more authorsIn IEEE/RSJ International Conference on Intelligent Robots and Systems, 2024Scene completion and forecasting are two popular perception problems in research for mobile agents like autonomous vehicles. Existing approaches treat the two problems in isolation, resulting in a separate perception of the two aspects. In this paper, we introduce a novel LiDAR perception task of Occupancy Completion and Forecasting (OCF) in the context of autonomous driving to unify these aspects into a cohesive framework. This task requires new algorithms to address three challenges altogether: (1) sparse-to-dense reconstruction, (2) partial-to-complete hallucination, and (3) 3D-to-4D prediction. To enable supervision and evaluation, we curate a large-scale dataset termed OCFBench from public autonomous driving datasets. We analyze the performance of closely related existing baseline models and our own ones on our dataset. We envision that this research will inspire and call for further investigation in this evolving and crucial area of 4D perception.
- CVPR
 Multiagent Multitraversal Multimodal Self-Driving: Open MARS DatasetYiming Li, Zhiheng Li, Nuo Chen, and 5 more authorsIn IEEE Conference on Computer Vision and Pattern Recognition, 2024
Multiagent Multitraversal Multimodal Self-Driving: Open MARS DatasetYiming Li, Zhiheng Li, Nuo Chen, and 5 more authorsIn IEEE Conference on Computer Vision and Pattern Recognition, 2024Large-scale datasets have fueled recent advancements in AI-based autonomous vehicle research. However, these datasets are usually collected from a single vehicle’s one-time pass of a certain location, lacking multiagent interactions or repeated traversals of the same place. Such information could lead to transformative enhancements in autonomous vehicles’ perception, prediction, and planning capabilities. To bridge this gap, in collaboration with the self-driving company May Mobility, we present MARS dataset which unifies scenarios that enable MultiAgent, multitraveRSal, and multimodal autonomous vehicle research. More specifically, MARS is collected with a fleet of autonomous vehicles driving within a certain geographical area. Each vehicle has its own route and different vehicles may appear at nearby locations. Each vehicle is equipped with a LiDAR and surround-view RGB cameras. We curate two subsets in MARS: one facilitates collaborative driving with multiple vehicles simultaneously present at the same location, and the other enables memory retrospection through asynchronous traversals of the same location by multiple vehicles. We conduct experiments in place recognition and neural reconstruction. More importantly, MARS introduces new research opportunities and challenges such as multitraversal 3D reconstruction, multiagent perception, and unsupervised object discovery. Our data and codes can be found at https://ai4ce.github.io/MARS/.
- ICRA
 EgoPAT3Dv2: Predicting 3D Action Target from 2D Egocentric Vision for Human-Robot InteractionIrving Fang, Yuzhong Chen, Yifan Wang, and 8 more authorsIn IEEE International Conference on Robotics and Automation, 2024
EgoPAT3Dv2: Predicting 3D Action Target from 2D Egocentric Vision for Human-Robot InteractionIrving Fang, Yuzhong Chen, Yifan Wang, and 8 more authorsIn IEEE International Conference on Robotics and Automation, 2024A robot’s ability to anticipate the 3D action target location of a hand’s movement from egocentric videos can greatly improve safety and efficiency in human-robot interaction (HRI). While previous research predominantly focused on semantic action classification or 2D target region prediction, we argue that predicting the action target’s 3D coordinate could pave the way for more versatile downstream robotics tasks, especially given the increasing prevalence of headset devices. This study expands EgoPAT3D, the sole dataset dedicated to egocentric 3D action target prediction. We augment both its size and diversity, enhancing its potential for generalization. Moreover, we substantially enhance the baseline algorithm by introducing a large pre-trained model and human prior knowledge. Remarkably, our novel algorithm can now achieve superior prediction outcomes using solely RGB images, eliminating the previous need for 3D point clouds and IMU input. Furthermore, we deploy our enhanced baseline algorithm on a real-world robotic platform to illustrate its practical utility in straightforward HRI tasks. The demonstrations showcase the real-world applicability of our advancements and may inspire more HRI use cases involving egocentric vision. All code and data are open-sourced and can be found on the project website.
- ICRA
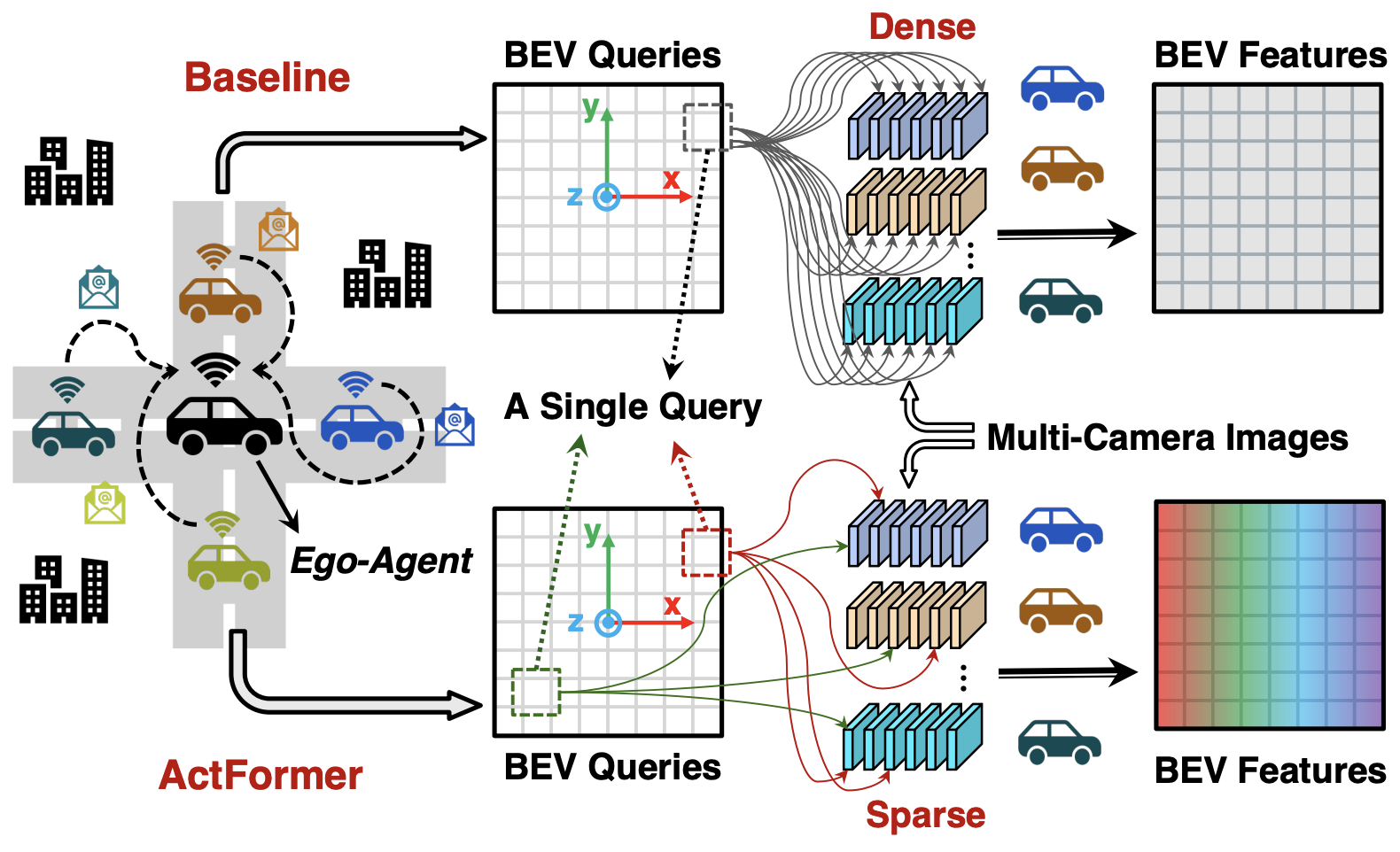 Actformer: Scalable collaborative perception via active queriesSuozhi Huang, Juexiao Zhang, Yiming Li, and 1 more authorIn IEEE International Conference on Robotics and Automation, 2024
Actformer: Scalable collaborative perception via active queriesSuozhi Huang, Juexiao Zhang, Yiming Li, and 1 more authorIn IEEE International Conference on Robotics and Automation, 2024Collaborative perception leverages rich visual observations from multiple robots to extend a single robot’s perception ability beyond its field of view. Many prior works receive messages broadcast from all collaborators, leading to a scalability challenge when dealing with a large number of robots and sensors. In this work, we aim to address \textitscalable camera-based collaborative perception with a Transformer-based architecture. Our key idea is to enable a single robot to intelligently discern the relevance of the collaborators and their associated cameras according to a learned spatial prior. This proactive understanding of the visual features’ relevance does not require the transmission of the features themselves, enhancing both communication and computation efficiency. Specifically, we present ActFormer, a Transformer that learns bird’s eye view (BEV) representations by using predefined BEV queries to interact with multi-robot multi-camera inputs. Each BEV query can actively select relevant cameras for information aggregation based on pose information, instead of interacting with all cameras indiscriminately. Experiments on the V2X-Sim dataset demonstrate that ActFormer improves the detection performance from 29.89% to 45.15% in terms of AP@0.7 with about 50% fewer queries, showcasing the effectiveness of ActFormer in multi-agent collaborative 3D object detection.
- RA-L
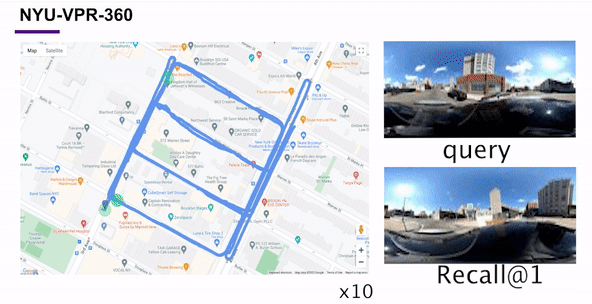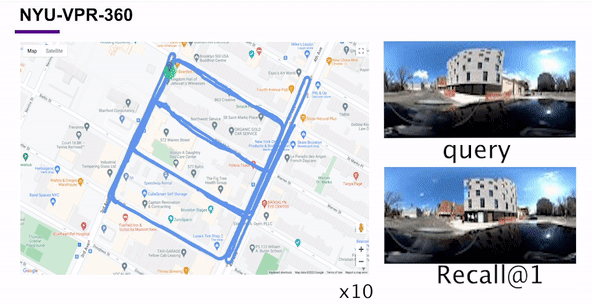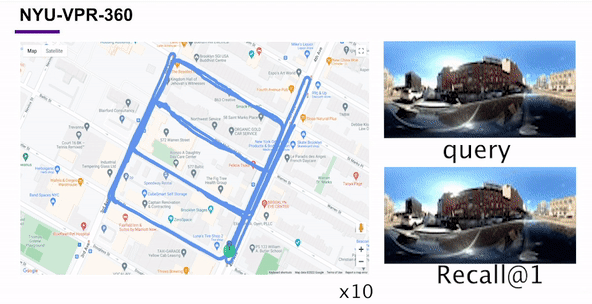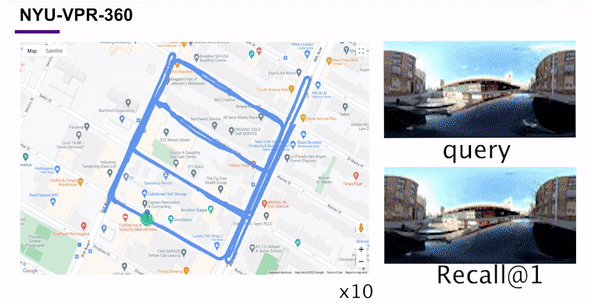 Self-Supervised Visual Place Recognition by Mining Temporal and Feature NeighborhoodsChao Chen, Xinhao Liu, Xuchu Xu, and 4 more authorsIEEE Robotics and Automation Letters, 2024
Self-Supervised Visual Place Recognition by Mining Temporal and Feature NeighborhoodsChao Chen, Xinhao Liu, Xuchu Xu, and 4 more authorsIEEE Robotics and Automation Letters, 2024Visual place recognition (VPR) using deep networks has achieved state-of-the-art performance. However, most of the related approaches require a training set with ground truth sensor poses to obtain the positive and negative samples of each observation’s spatial neighborhoods. When such knowledge is unknown, the temporal neighborhoods from a sequentially collected data stream could be exploited for self-supervision, although with suboptimal performance. Inspired by noisy label learning, we propose a novel self-supervised VPR framework that uses both the temporal neighborhoods and the learnable feature neighborhoods to discover the unknown spatial neighborhoods. Our method follows an iterative training paradigm which alternates between: (1) representation learning with data augmentation, (2) positive set expansion to include the current feature space neighbors, and (3) positive set contraction via geometric verification. We conduct comprehensive experiments on both simulated and real datasets, with input of both images and point clouds. The results demonstrate that our method outperforms the baselines in both recall rate, robustness, and a novel metric we proposed for VPR, the orientation diversity.











2023
- RA-L
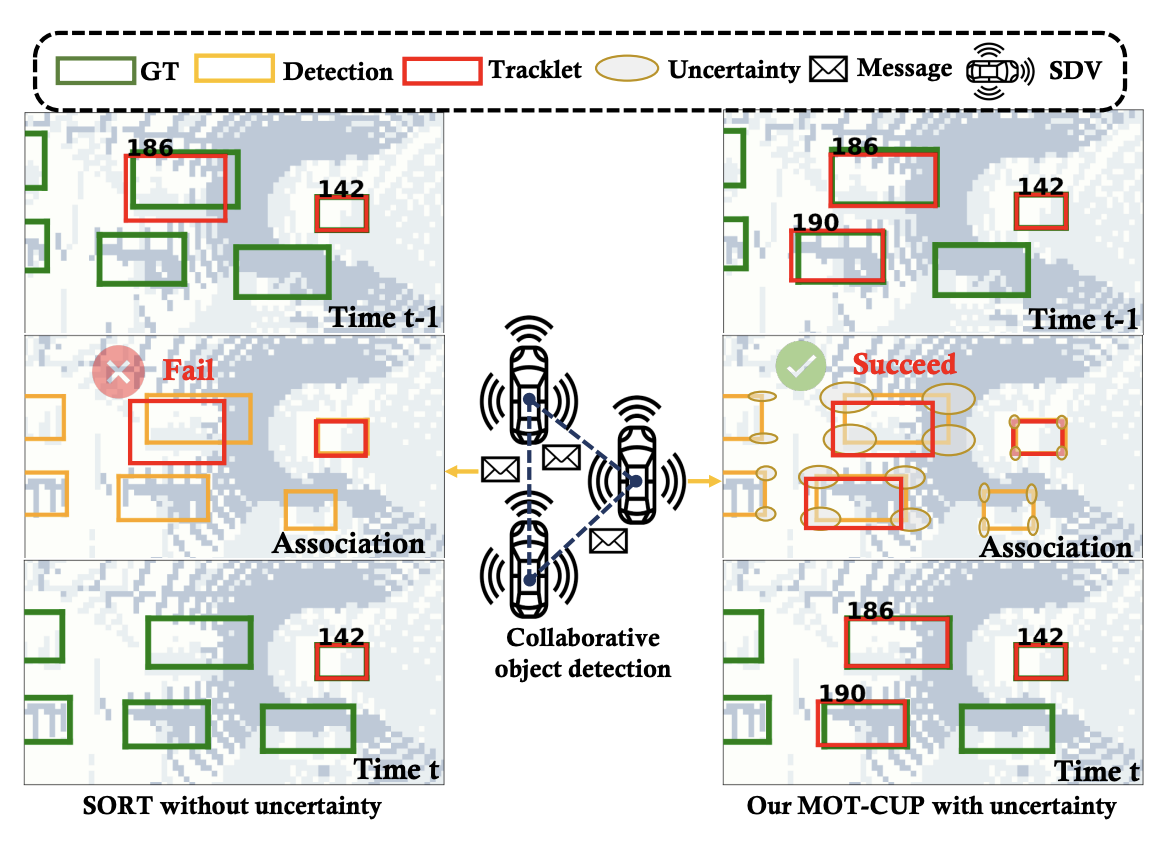 Collaborative Multi-Object Tracking with Conformal Uncertainty PropagationSanbao Su, Songyang Han, Yiming Li, and 4 more authorsIEEE Robotics and Automation Letters, 2023
Collaborative Multi-Object Tracking with Conformal Uncertainty PropagationSanbao Su, Songyang Han, Yiming Li, and 4 more authorsIEEE Robotics and Automation Letters, 2023Object detection and multiple object tracking (MOT) are essential components of self-driving systems. Accurate detection and uncertainty quantification are both critical for onboard modules, such as perception, prediction, and planning, to improve the safety and robustness of autonomous vehicles. Collaborative object detection (COD) has been proposed to improve detection accuracy and reduce uncertainty by leveraging the viewpoints of multiple agents. However, little attention has been paid on how to leverage the uncertainty quantification from COD to enhance MOT performance. In this paper, as the first attempt, we design the uncertainty propagation framework to address this challenge, called MOT-CUP. Our framework first quantifies the uncertainty of COD through direct modeling and conformal prediction, and propogates this uncertainty information during the motion prediction and association steps. MOT-CUP is designed to work with different collaborative object detectors and baseline MOT algorithms. We evaluate MOT-CUP on V2X-Sim, a comprehensive collaborative perception dataset, and demonstrate a 2% improvement in accuracy and a 2.67X reduction in uncertainty compared to the baselines, e.g., SORT and ByteTrack. MOT-CUP demonstrates the importance of uncertainty quantification in both COD and MOT, and provides the first attempt to improve the accuracy and reduce the uncertainty in MOT based on COD through uncertainty propogation.
- RSS
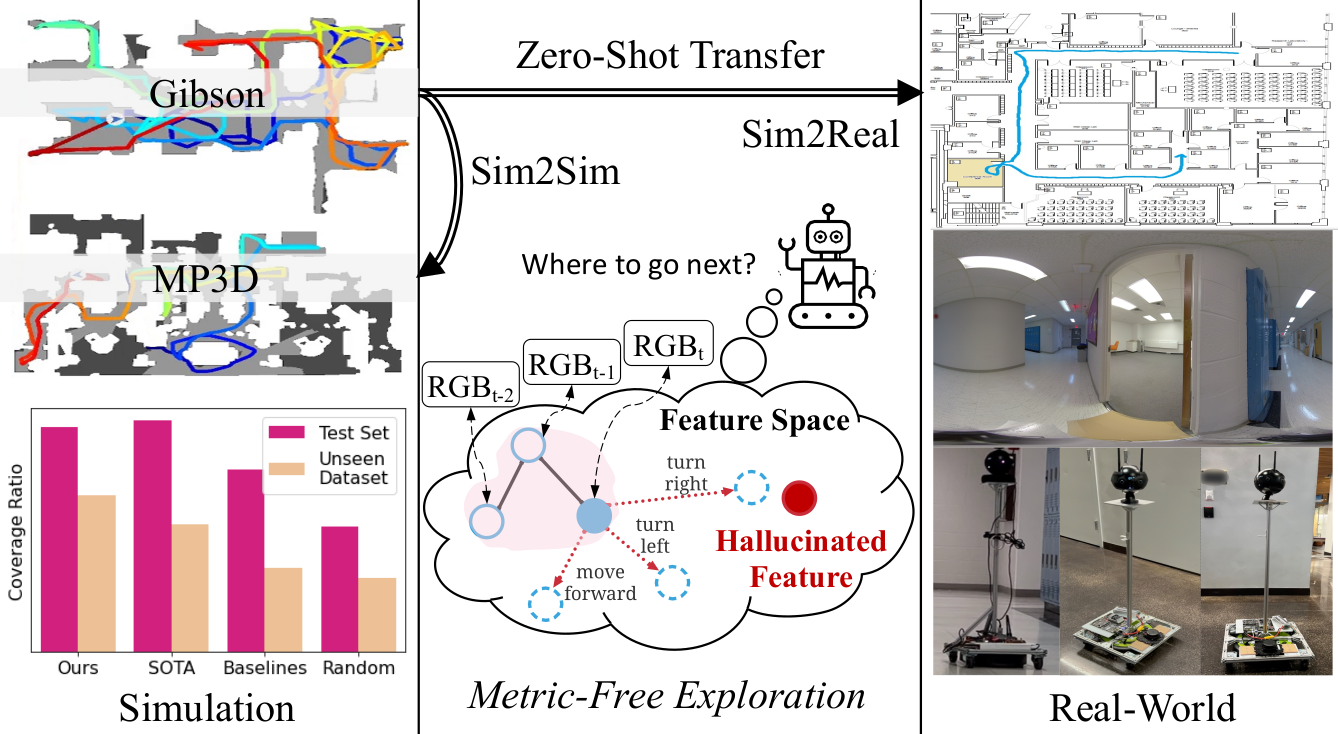 Metric-Free Exploration for Topological Mapping by Task and Motion Imitation in Feature SpaceYuhang He, Irving Fang, Yiming Li, and 2 more authorsIn Proceedings of Robotics: Science and Systems, 2023
Metric-Free Exploration for Topological Mapping by Task and Motion Imitation in Feature SpaceYuhang He, Irving Fang, Yiming Li, and 2 more authorsIn Proceedings of Robotics: Science and Systems, 2023We propose DeepExplorer, a simple and lightweight metric-free exploration method for topological mapping of unknown environments. It performs task and motion planning (TAMP) entirely in image feature space. The task planner is a recurrent network using the latest image observation sequence to hallucinate a feature as the next-best exploration goal. The motion planner then utilizes the current and the hallucinated features to generate an action taking the agent towards that goal. The two planners are jointly trained via deeply-supervised imitation learning from expert demonstrations. During exploration, we iteratively call the two planners to predict the next action, and the topological map is built by constantly appending the latest image observation and action to the map and using visual place recognition (VPR) for loop closing. The resulting topological map efficiently represents an environment’s connectivity and traversability, so it can be used for tasks such as visual navigation. We show DeepExplorer’s exploration efficiency and strong sim2sim generalization capability on large-scale simulation datasets like Gibson and MP3D. Its effectiveness is further validated via the image-goal navigation performance on the resulting topological map. We further show its strong zero-shot sim2real generalization capability in real-world experiments.
- ICCV
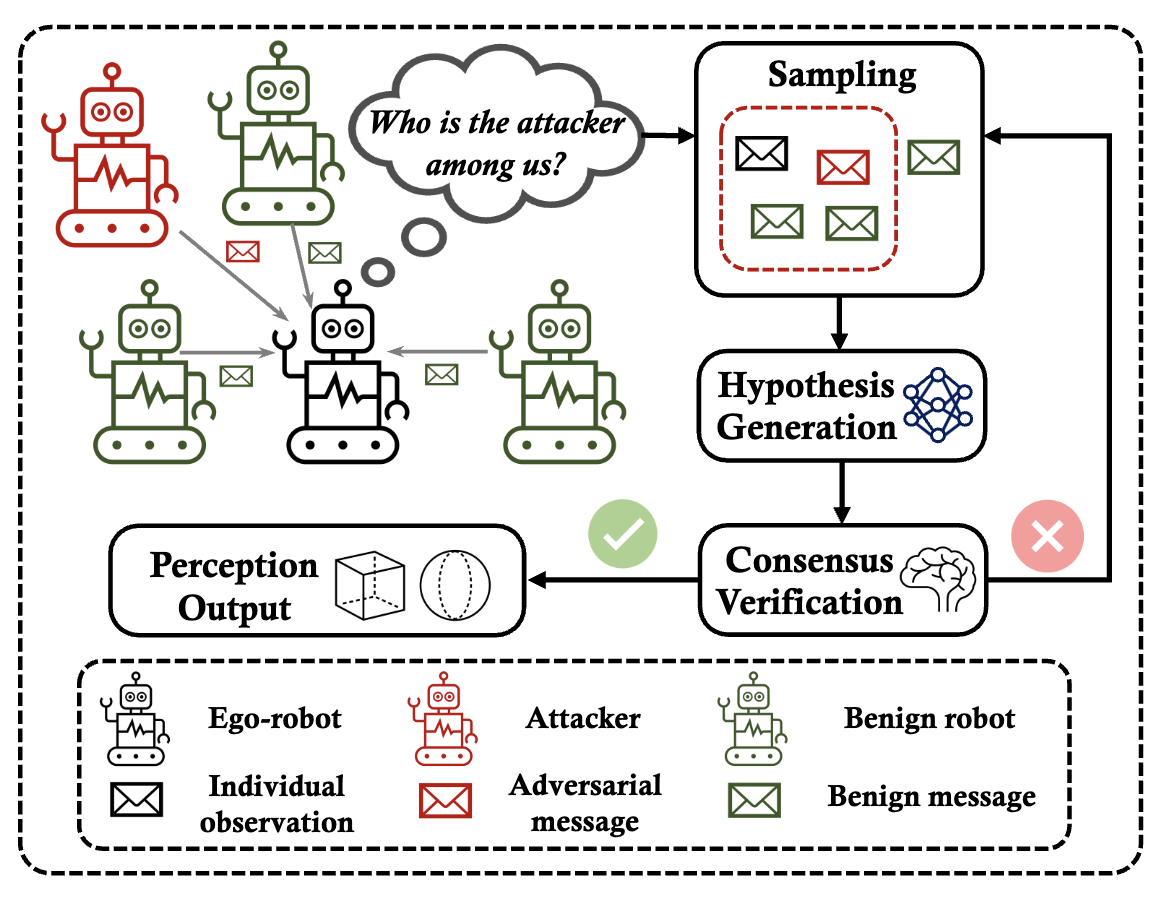 Among Us: Adversarially Robust Collaborative Perception by ConsensusYiming Li, Qi Fang, Jiamu Bai, and 3 more authorsIn IEEE International Conference on Computer Vision, 2023
Among Us: Adversarially Robust Collaborative Perception by ConsensusYiming Li, Qi Fang, Jiamu Bai, and 3 more authorsIn IEEE International Conference on Computer Vision, 2023Multiple robots could perceive a scene (e.g., detect objects) collaboratively better than individuals, although easily suffer from adversarial attacks when using deep learning. This could be addressed by the adversarial defense, but its training requires the often-unknown attacking mechanism. Differently, we propose ROBOSAC, a novel sampling-based defense strategy generalizable to unseen attackers. Our key idea is that collaborative perception should lead to consensus rather than dissensus in results compared to individual perception. This leads to our hypothesize-and-verify framework: perception results with and without collaboration from a random subset of teammates are compared until reaching a consensus. In such a framework, more teammates in the sampled subset often entail better perception performance but require longer sampling time to reject potential attackers. Thus, we derive how many sampling trials are needed to ensure the desired size of an attacker-free subset, or equivalently, the maximum size of such a subset that we can successfully sample within a given number of trials. We validate our method on the task of collaborative 3D object detection in autonomous driving scenarios.
- ICCV
 PVT++: A Simple End-to-End Latency-Aware Visual Tracking FrameworkBowen Li, Ziyuan Huang, Junjie Ye, and 4 more authorsIn IEEE International Conference on Computer Vision, 2023
PVT++: A Simple End-to-End Latency-Aware Visual Tracking FrameworkBowen Li, Ziyuan Huang, Junjie Ye, and 4 more authorsIn IEEE International Conference on Computer Vision, 2023Visual object tracking is essential to intelligent robots. Most existing approaches have ignored the online latency that can cause severe performance degradation during real-world processing. Especially for unmanned aerial vehicles (UAVs), where robust tracking is more challenging and onboard computation is limited, the latency issue can be fatal. In this work, we present a simple framework for end-to-end latency-aware tracking, i.e., end-to-end predictive visual tracking (PVT++). Unlike existing solutions that naively append Kalman Filters after trackers, PVT++ can be jointly optimized, so that it takes not only motion information but can also leverage the rich visual knowledge in most pre-trained tracker models for robust prediction. Besides, to bridge the training-evaluation domain gap, we propose a relative motion factor, empowering PVT++ to generalize to the challenging and complex UAV tracking scenes. These careful designs have made the small-capacity lightweight PVT++ a widely effective solution. Additionally, this work presents an extended latency-aware evaluation benchmark for assessing an any-speed tracker in the online setting. Empirical results on a robotic platform from the aerial perspective show that PVT++ can achieve significant performance gain on various trackers and exhibit higher accuracy than prior solutions, largely mitigating the degradation brought by latency.
- CVPR Highlight
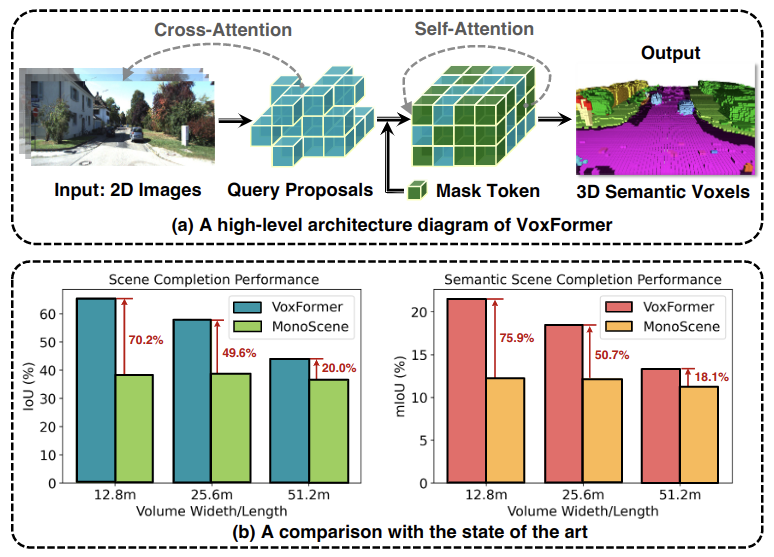 VoxFormer: Sparse Voxel Transformer for Camera-based 3D Semantic Scene CompletionYiming Li, Zhiding Yu, Christopher Choy, and 5 more authorsIn IEEE Conference on Computer Vision and Pattern Recognition, 2023
VoxFormer: Sparse Voxel Transformer for Camera-based 3D Semantic Scene CompletionYiming Li, Zhiding Yu, Christopher Choy, and 5 more authorsIn IEEE Conference on Computer Vision and Pattern Recognition, 2023Humans can easily imagine the complete 3D geometry of occluded objects and scenes. This appealing ability is vital for recognition and understanding. To enable such capability in AI systems, we propose VoxFormer, a Transformerbased semantic scene completion framework that can output complete 3D volumetric semantics from only 2D images. Our framework adopts a two-stage design where we start from a sparse set of visible and occupied voxel queries from depth estimation, followed by a densification stage that generates dense 3D voxels from the sparse ones. A key idea of this design is that the visual features on 2D images correspond only to the visible scene structures rather than the occluded or empty spaces. Therefore, starting with the featurization and prediction of the visible structures is more reliable. Once we obtain the set of sparse queries, we apply a masked autoencoder design to propagate the information to all the voxels by self-attention. Experiments on SemanticKITTI show that VoxFormer outperforms the state of the art with a relative improvement of 20.0% in geometry and 18.1% in semantics and reduces GPU memory during training to less than 16GB. Our code is available on https://github.com/NVlabs/VoxFormer.
- CVPR
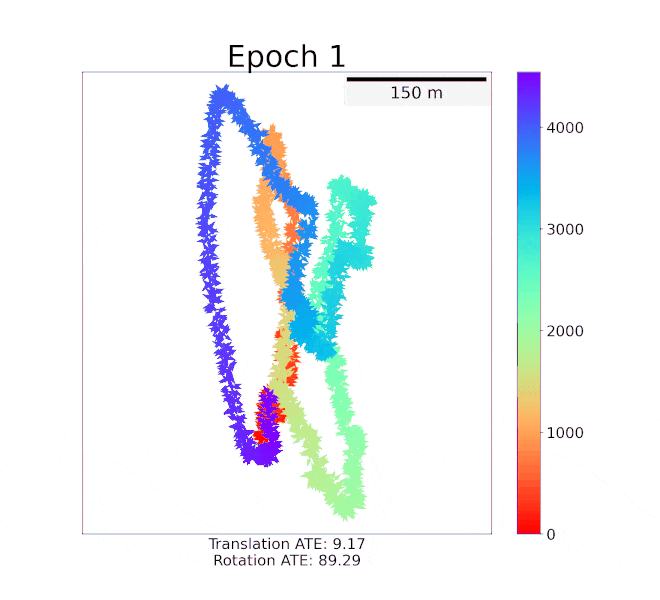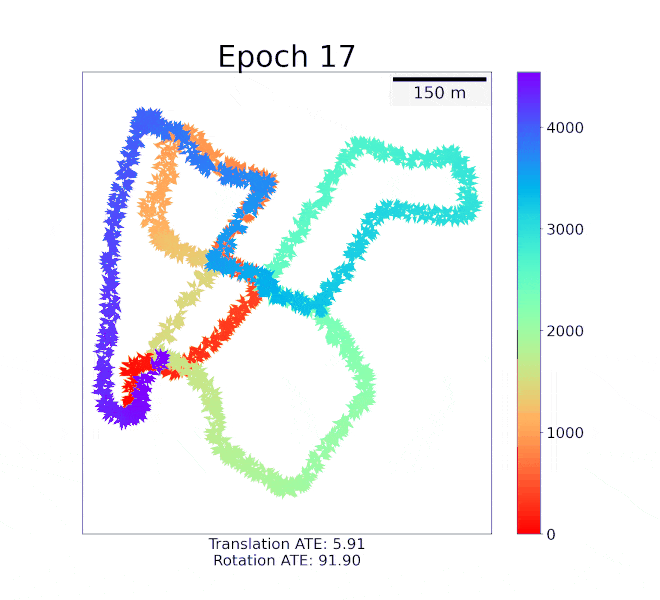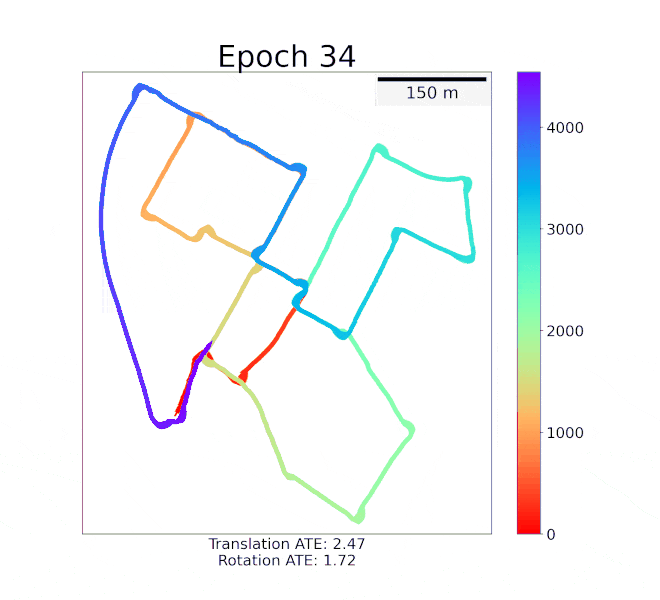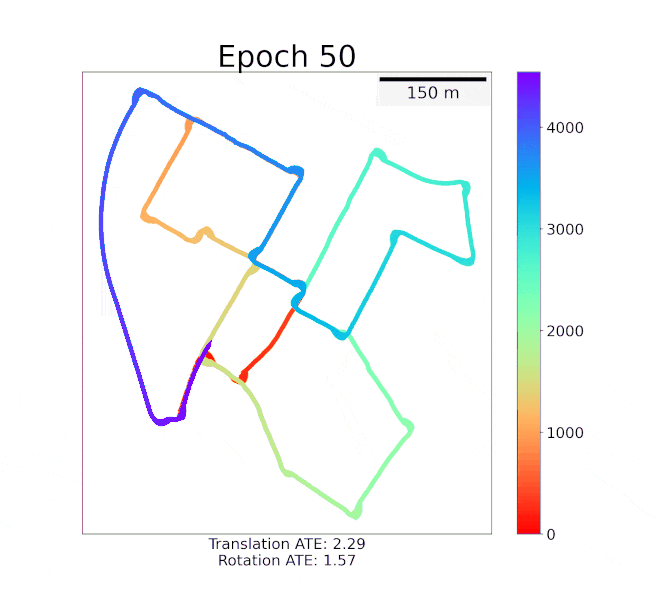 DeepMapping2: Self-Supervised Large-Scale LiDAR Map OptimizationChao Chen, Xinhao Liu, Yiming Li, and 2 more authorsIn IEEE Conference on Computer Vision and Pattern Recognition, 2023
DeepMapping2: Self-Supervised Large-Scale LiDAR Map OptimizationChao Chen, Xinhao Liu, Yiming Li, and 2 more authorsIn IEEE Conference on Computer Vision and Pattern Recognition, 2023LiDAR mapping is important yet challenging in self-driving and mobile robotics. To tackle such a global point cloud registration problem, DeepMapping [1] converts the complex map estimation into a self-supervised training of simple deep networks. Despite its broad convergence range on small datasets, DeepMapping still cannot produce satisfactory results on large-scale datasets with thousands of frames. This is due to the lack of loop closures and exact cross-frame point correspondences, and the slow convergence of its global localization network. We propose DeepMapping2 by adding two novel techniques to address these issues: (1) organization of training batch based on map topology from loop closing, and (2) self-supervised local-to-global point consistency loss leveraging pairwise registration. Our experiments and ablation studies on public datasets such as KITTI, NCLT, and Nebula demonstrate the effectiveness of our method.
- ICRA
 Uncertainty Quantification of Collaborative Detection for Self-DrivingSanbao Su, Yiming Li, Sihong He, and 4 more authorsIn IEEE International Conference on Robotics and Automation, 2023
Uncertainty Quantification of Collaborative Detection for Self-DrivingSanbao Su, Yiming Li, Sihong He, and 4 more authorsIn IEEE International Conference on Robotics and Automation, 2023Sharing information between connected and autonomous vehicles (CAVs) fundamentally improves the performance of collaborative object detection for self-driving. However, CAVs still have uncertainties on object detection due to practical challenges, which will affect the later modules in self-driving such as planning and control. Hence, uncertainty quantification is crucial for safety-critical systems such as CAVs. Our work is the first to estimate the uncertainty of collaborative object detection. We propose a novel uncertainty quantification method, called Double-M Quantification, which tailors a moving block bootstrap (MBB) algorithm with direct modeling of the multivariant Gaussian distribution of each corner of the bounding box. Our method captures both the epistemic uncertainty and aleatoric uncertainty with one inference pass based on the offline Double-M training process. And it can be used with different collaborative object detectors. Through experiments on the comprehensive collaborative perception dataset, we show that our Double-M method achieves more than 4× improvement on uncertainty score and more than 3% accuracy improvement, compared with the state-of-the-art uncertainty quantification methods.
- RA-L
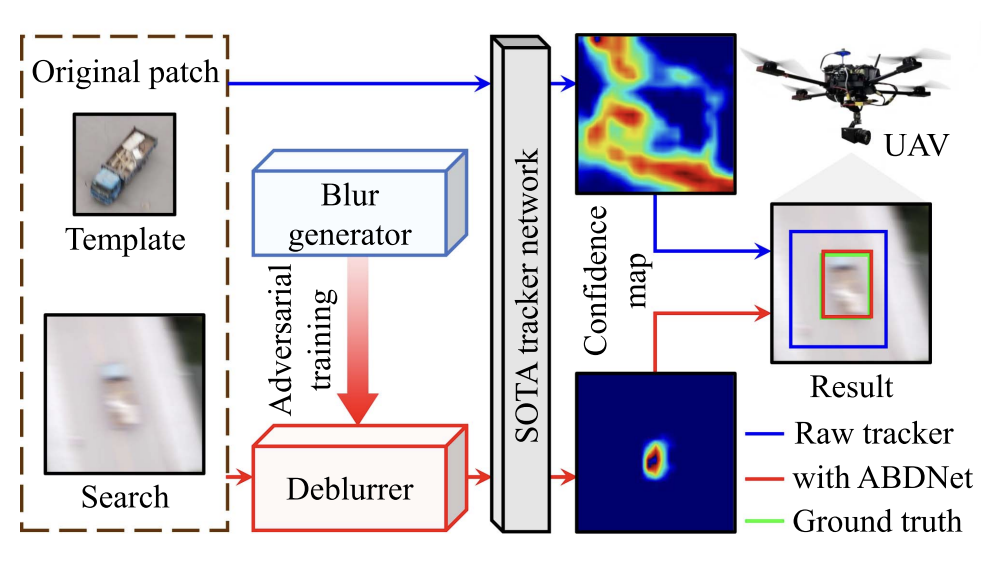 Adversarial Blur-Deblur Network for Robust UAV TrackingHaobo Zuo, Changhong Fu, Sihang Li, and 3 more authorsIEEE Robotics and Automation Letters, 2023
Adversarial Blur-Deblur Network for Robust UAV TrackingHaobo Zuo, Changhong Fu, Sihang Li, and 3 more authorsIEEE Robotics and Automation Letters, 2023Unmanned aerial vehicle (UAV) tracking has been widely applied in real-world applications such as surveillance and monitoring. However, the inherent high maneuverability and agility of UAV often lead to motion blur, which can impair the visual appearance of the target object and easily degrade the existing trackers. To overcome this challenge, this work proposes a tracking-oriented adversarial blur-deblur network (ABDNet), composed of a novel deblurrer to recover the visual appearance of the tracked object, and a brand-new blur generator to produce realistic blurry images for adversarial training. More specifically, the deblurrer progressively refines the features through pixel-wise, spatial-wise, and channel-wise stages to achieve excellent deblurring performance. The blur generator adaptively fuses an image sequence with a learnable kernel to create realistic blurry images. During training, ABDNet is plugged into the state-of-the-art real-time trackers and trained with blurring-deblurring loss as well as tracking loss. During inference, the blur generator is removed, while the deblurrer and the tracker can work together for UAV tracking. Extensive experiments in both public datasets and real-world testing have validated the effectiveness of ABDNet.
- RA-L
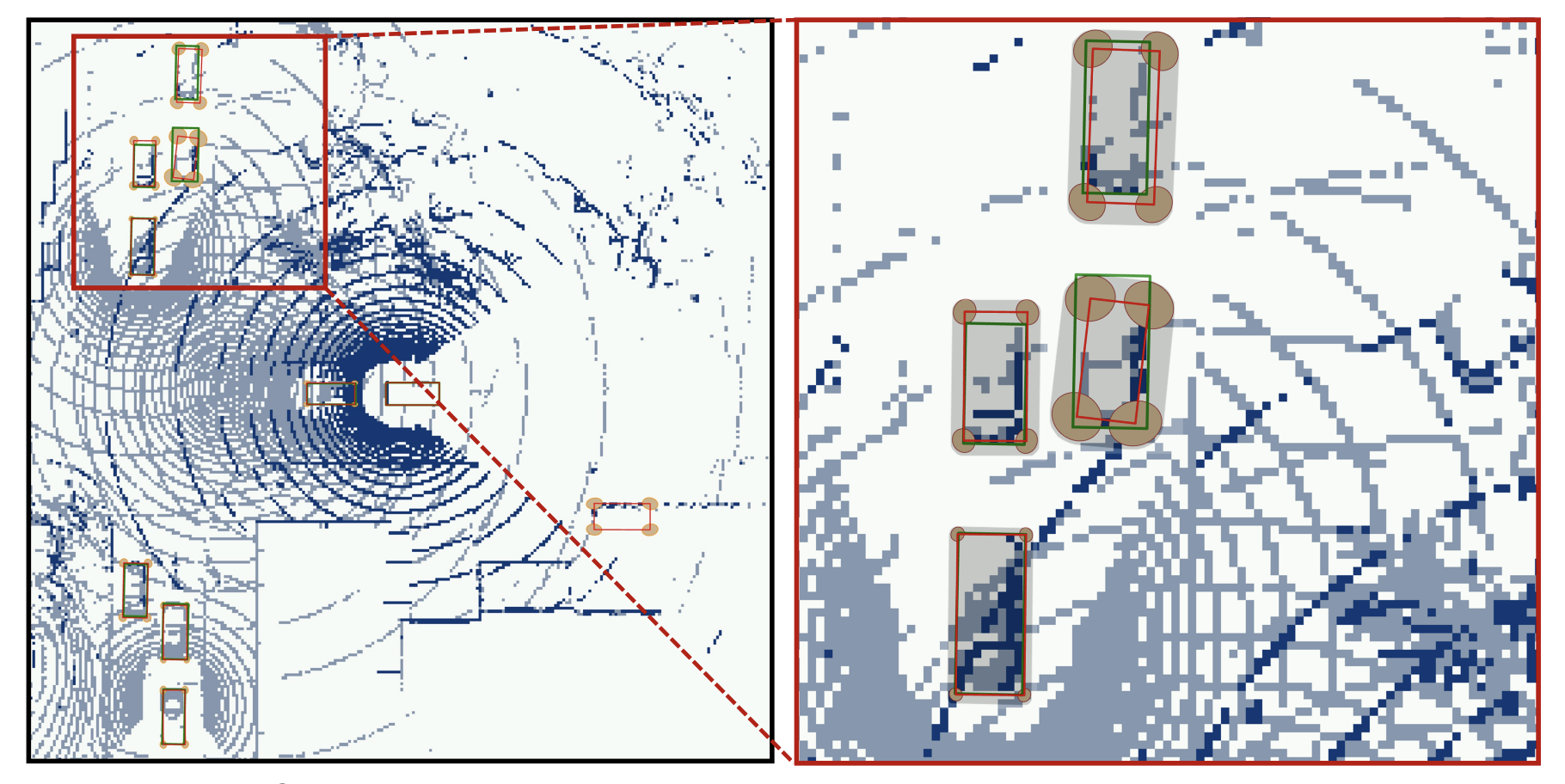
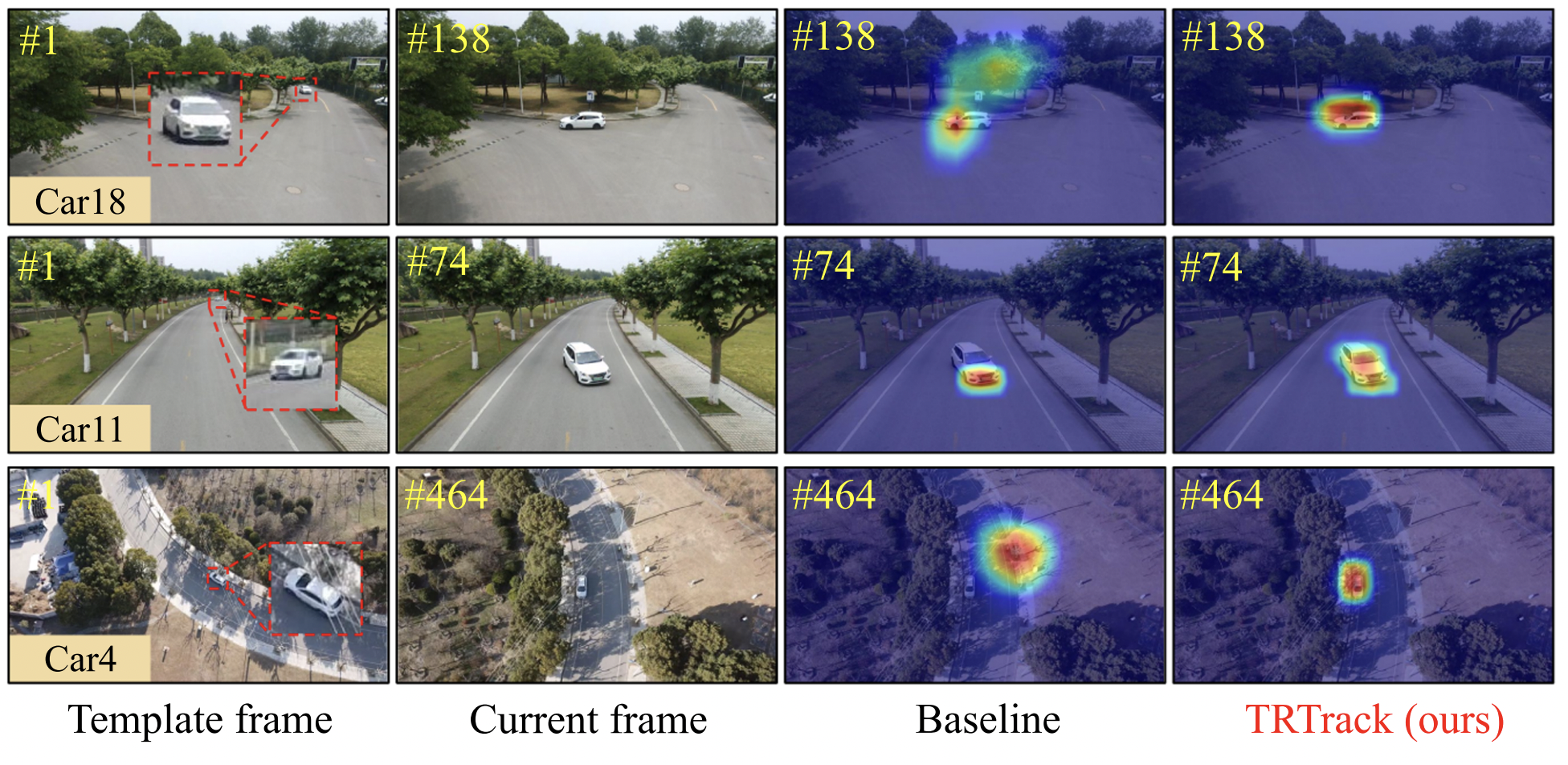 Boosting UAV Tracking with Voxel-based Trajectory-Aware Pre-TrainingSihang Li, Changhong Fu, Kunhan Lu, and 3 more authorsIEEE Robotics and Automation Letters, 2023
Boosting UAV Tracking with Voxel-based Trajectory-Aware Pre-TrainingSihang Li, Changhong Fu, Kunhan Lu, and 3 more authorsIEEE Robotics and Automation Letters, 2023Siamese network-based object tracking has remarkably promoted the automatic capability for highlymaneuvered unmanned aerial vehicles (UAVs). However, the leading-edge tracking framework often depends on template matching, making it trapped when facing multiple views of object in consecutive frames. Moreover, the general imagelevel pretrained backbone can overfit to holistic representations, causing the misalignment to learn object-level properties in UAV tracking. To tackle these issues, this work presents TRTrack, a comprehensive framework to fully exploit the stereoscopic representation for UAV tracking. Specifically, a novel pretraining paradigm method is proposed. Through trajectoryaware reconstruction training, the capability of the backbone to extract stereoscopic structure feature is strengthened without any parameter increment. Accordingly, an innovative hierarchical self-attention Transformer is proposed to capture the local detail information and global structure knowledge. For optimizing the correlation map, we proposed a novel spatial correlation refinement (SCR) module, which promotes the capability of modeling the long-range spatial dependencies. Comprehensive experiments on three UAV challenging benchmarks demonstrate that the proposed TRTrack achieves superior UAV tracking performance in both precision and efficiency. Quantitative tests in real-world settings fully prove the effectiveness of our work.









2022
- CoRL
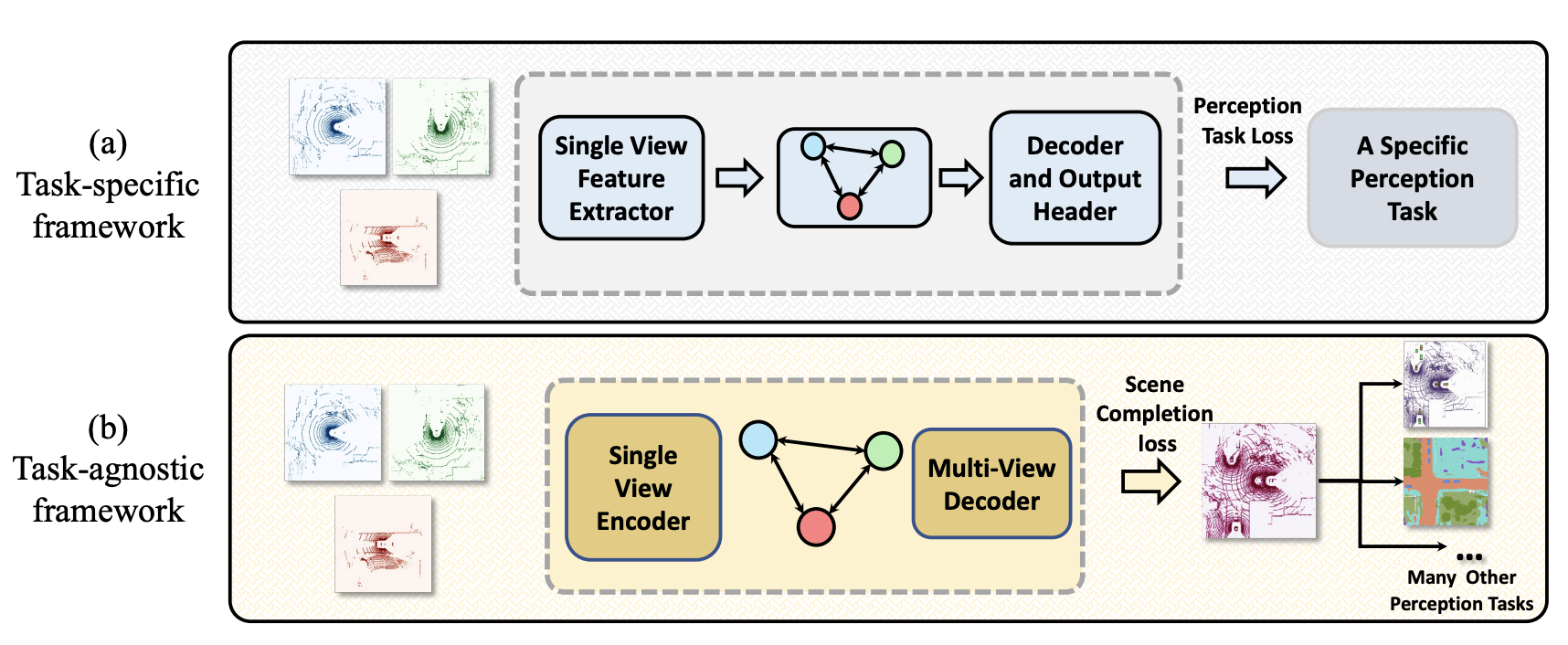 Multi-Robot Scene Completion: Towards Task-Agnostic Collaborative PerceptionYiming Li, Juexiao Zhang, Dekun Ma, and 2 more authorsIn 6th Conference on Robot Learning, 2022
Multi-Robot Scene Completion: Towards Task-Agnostic Collaborative PerceptionYiming Li, Juexiao Zhang, Dekun Ma, and 2 more authorsIn 6th Conference on Robot Learning, 2022Collaborative perception learns how to share information among multiple robots to perceive the environment better than individually done. Past research on this has been task-specific, such as detection or segmentation. Yet this leads to different information sharing for different tasks, hindering the large-scale deployment of collaborative perception. We propose the first task-agnostic collaborative perception paradigm that learns a single collaboration module in a self-supervised manner for different downstream tasks. This is done by a novel task termed multi-robot scene completion, where each robot learns to effectively share information for reconstructing a complete scene viewed by all robots. Moreover, we propose a spatiotemporal autoencoder (STAR) that amortizes over time the communication cost by spatial sub-sampling and temporal mixing. Extensive experiments validate our method’s effectiveness on scene completion and collaborative perception in autonomous driving scenarios.
- CVPR
 Egocentric Prediction of Action Target in 3DYiming Li, Ziang Cao, Andrew Liang, and 4 more authorsIn IEEE Conference on Computer Vision and Pattern Recognition, Jun 2022
Egocentric Prediction of Action Target in 3DYiming Li, Ziang Cao, Andrew Liang, and 4 more authorsIn IEEE Conference on Computer Vision and Pattern Recognition, Jun 2022We are interested in anticipating as early as possible the target location of a person’s object manipulation action in a 3D workspace from egocentric vision. It is important in fields like human-robot collaboration, but has not yet received enough attention from vision and learning communities. To stimulate more research on this challenging egocentric vision task, we propose a large multimodality dataset of more than 1 million frames of RGB-D and IMU streams, and provide evaluation metrics based on our high-quality 2D and 3D labels from semi-automatic annotation. Meanwhile, we design baseline methods using recurrent neural networks (RNNs) and conduct various ablation studies to validate their effectiveness. Our results demonstrate that this new task is worthy of further study by researchers in robotics, vision, and learning communities.
- RA-L
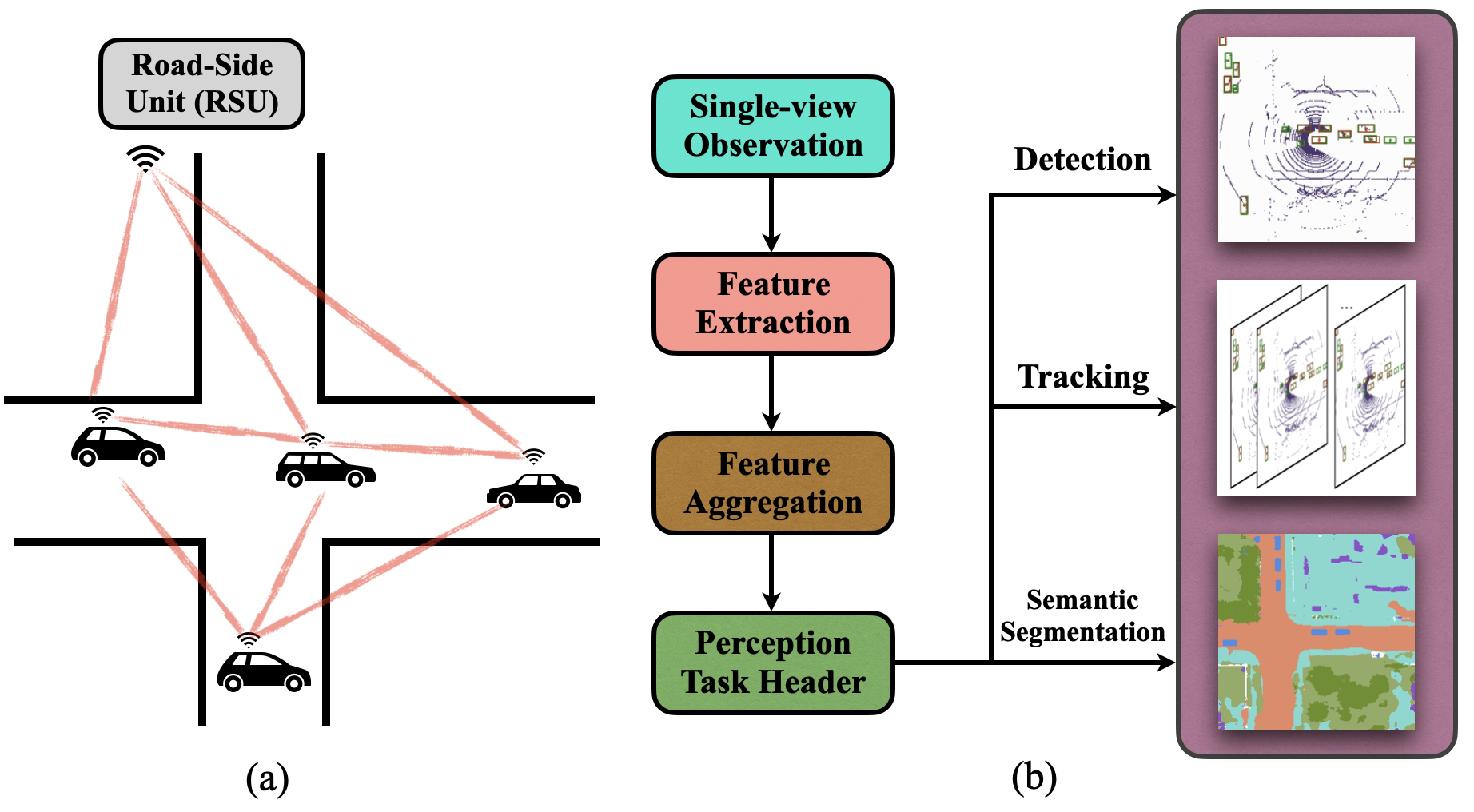 V2X-Sim: Multi-Agent Collaborative Perception Dataset and Benchmark for Autonomous DrivingYiming Li, Dekun Ma, Ziyan An, and 4 more authorsIEEE Robotics and Automation Letters, Jun 2022
V2X-Sim: Multi-Agent Collaborative Perception Dataset and Benchmark for Autonomous DrivingYiming Li, Dekun Ma, Ziyan An, and 4 more authorsIEEE Robotics and Automation Letters, Jun 2022Vehicle-to-everything (V2X) communication techniques enable the collaboration between vehicles and many other entities in the neighboring environment, which could fundamentally improve the perception system for autonomous driving. However, the lack of a public dataset significantly restricts the research progress of collaborative perception. To fill this gap, we present V2X-Sim, a comprehensive simulated multi-agent perception dataset for V2X-aided autonomous driving. V2X-Sim provides: (1) multi-agent sensor recordings from the road-side unit (RSU) and multiple vehicles that enable collaborative perception, (2) multi-modality sensor streams that facilitate multi-modality perception, and (3) diverse ground truths that support various perception tasks. Meanwhile, we build an open-source testbed and provide a benchmark for the state-of-the-art collaborative perception algorithms on three tasks, including detection, tracking and segmentation. V2X-Sim seeks to stimulate collaborative perception research for autonomous driving before realistic datasets become widely available.



2021
- NeurIPS
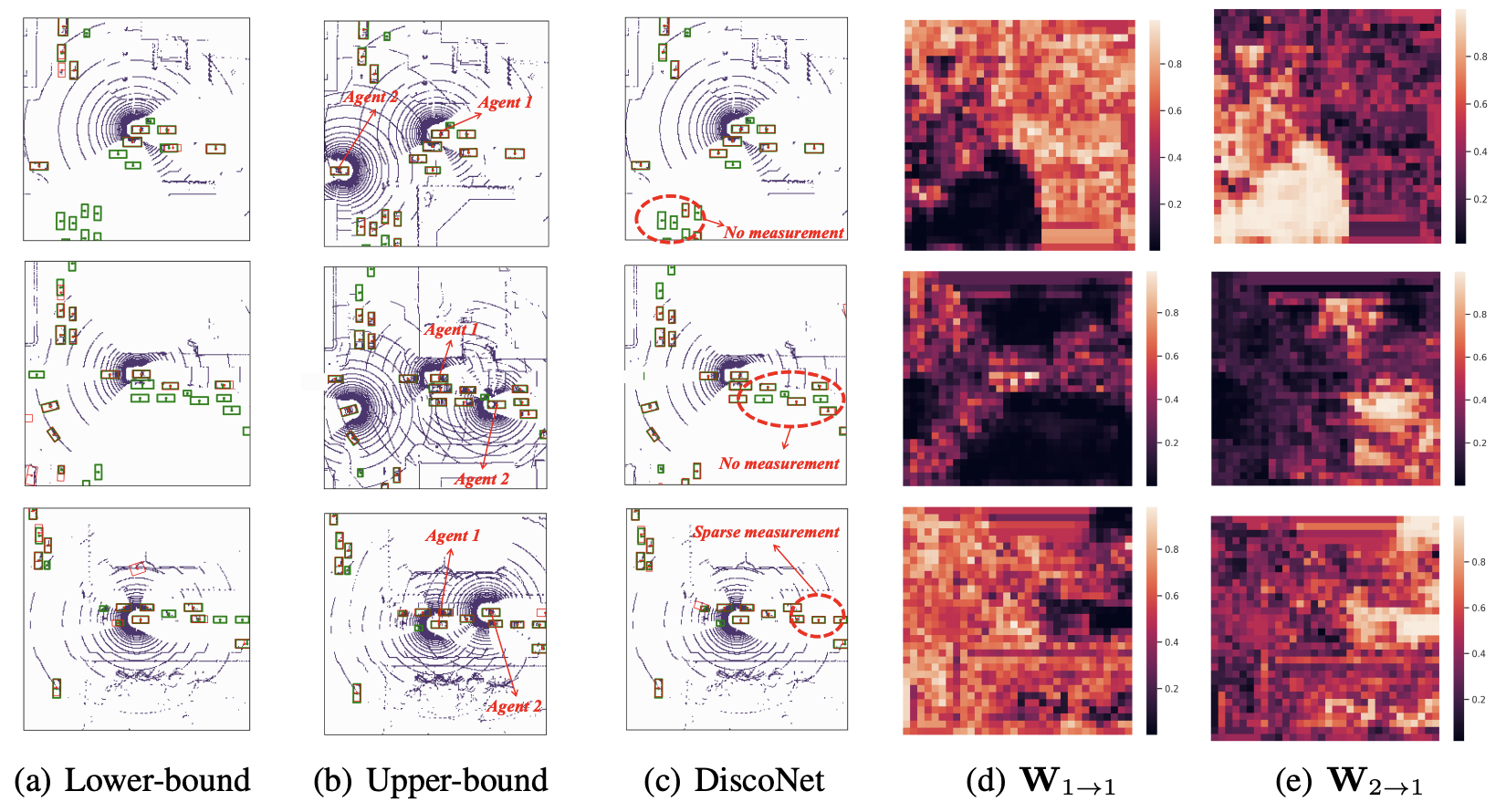 Learning Distilled Collaboration Graph for Multi-Agent PerceptionYiming Li, Shunli Ren, Pengxiang Wu, and 3 more authorsIn Advances in Neural Information Processing Systems, Jun 2021
Learning Distilled Collaboration Graph for Multi-Agent PerceptionYiming Li, Shunli Ren, Pengxiang Wu, and 3 more authorsIn Advances in Neural Information Processing Systems, Jun 2021To promote better performance-bandwidth trade-off for multi-agent perception, we propose a novel distilled collaboration graph (DiscoGraph) to model trainable, pose-aware, and adaptive collaboration among agents. Our key novelties lie in two aspects. First, we propose a teacher-student framework to train DiscoGraph via knowledge distillation. The teacher model employs an early collaboration with holistic-view inputs; the student model is based on intermediate collaboration with single-view inputs. Our framework trains DiscoGraph by constraining post-collaboration feature maps in the student model to match the correspondences in the teacher model. Second, we propose a matrix-valued edge weight in DiscoGraph. In such a matrix, each element reflects the inter-agent attention at a specific spatial region, allowing an agent to adaptively highlight the informative regions. During inference, we only need to use the student model named as the distilled collaboration network (DiscoNet). Attributed to the teacher-student framework, multiple agents with the shared DiscoNet could collaboratively approach the performance of a hypothetical teacher model with a holistic view. Our approach is validated on V2X-Sim 1.0, a large-scale multi-agent perception dataset that we synthesized using CARLA and SUMO co-simulation. Our quantitative and qualitative experiments in multi-agent 3D object detection show that DiscoNet could not only achieve a better performance-bandwidth trade-off than the state-of-the-art collaborative perception methods, but also bring more straightforward design rationale.
- ICCV Oral
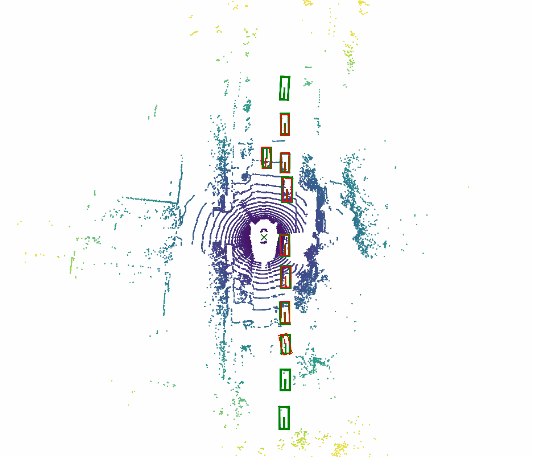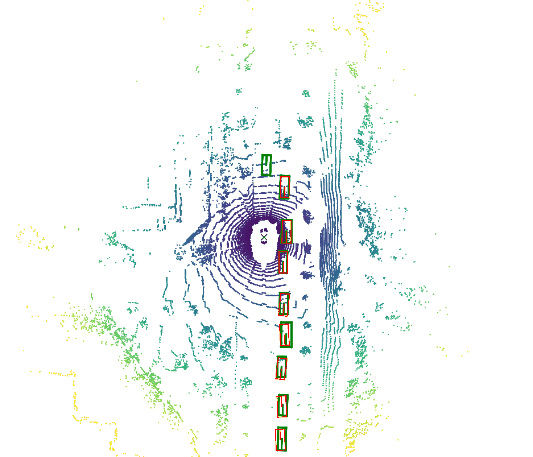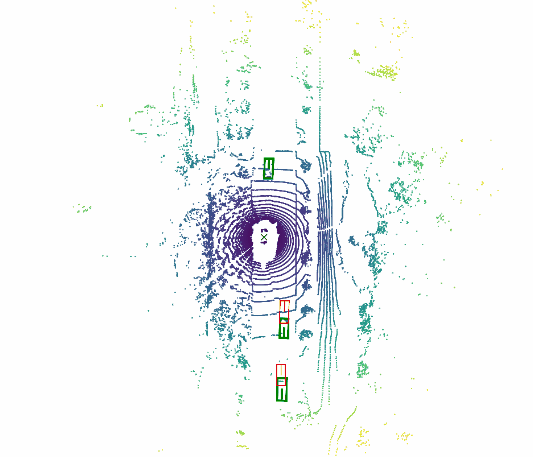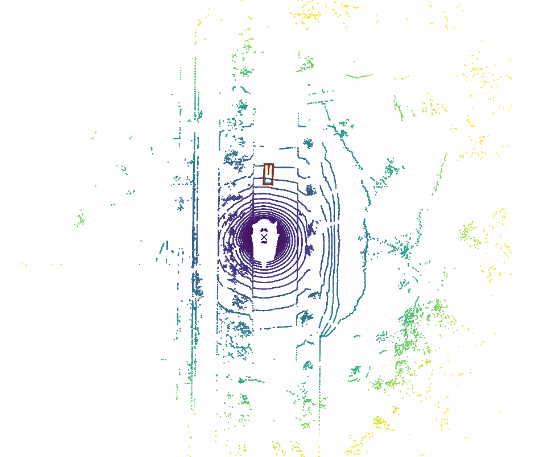 Fooling LiDAR Perception via Adversarial Trajectory PerturbationYiming Li, Congcong Wen, Felix Juefei-Xu, and 1 more authorIn IEEE International Conference on Computer Vision, Jun 2021
Fooling LiDAR Perception via Adversarial Trajectory PerturbationYiming Li, Congcong Wen, Felix Juefei-Xu, and 1 more authorIn IEEE International Conference on Computer Vision, Jun 2021LiDAR point clouds collected from a moving vehicle are functions of its trajectories, because the sensor motion needs to be compensated to avoid distortions. When autonomous vehicles are sending LiDAR point clouds to deep networks for perception and planning, could the motion compensation consequently become a wide-open backdoor in those networks, due to both the adversarial vulnerability of deep learning and GPS-based vehicle trajectory estimation that is susceptible to wireless spoofing? We demonstrate such possibilities for the first time: instead of directly attacking point cloud coordinates which requires tampering with the raw LiDAR readings, only adversarial spoofing of a self-driving car’s trajectory with small perturbations is enough to make safety-critical objects undetectable or detected with incorrect positions. Moreover, polynomial trajectory perturbation is developed to achieve a temporally-smooth and highly-imperceptible attack. Extensive experiments on 3D object detection have shown that such attacks not only lower the performance of the state-of-the-art detectors effectively, but also transfer to other detectors, raising a red flag for the community.
- ICCV
 HiFT: Hierarchical Feature Transformer for Aerial TrackingZiang Cao, Changhong Fu, Junjie Ye, and 2 more authorsIn IEEE International Conference on Computer Vision, Jun 2021
HiFT: Hierarchical Feature Transformer for Aerial TrackingZiang Cao, Changhong Fu, Junjie Ye, and 2 more authorsIn IEEE International Conference on Computer Vision, Jun 2021Most existing Siamese-based tracking methods execute the classification and regression of the target object based on the similarity maps. However, they either employ a single map from the last convolutional layer which degrades the localization accuracy in complex scenarios or separately use multiple maps for decision making, introducing intractable computations for aerial mobile platforms. Thus, in this work, we propose an efficient and effective hierarchical feature transformer (HiFT) for aerial tracking. Hierarchical similarity maps generated by multi-level convolutional layers are fed into the feature transformer to achieve the interactive fusion of spatial (shallow layers) and semantics cues (deep layers). Consequently, not only the global contextual information can be raised, facilitating the target search, but also our end-to-end architecture with the transformer can efficiently learn the interdependencies among multi-level features, thereby discovering a tracking-tailored feature space with strong discriminability. Comprehensive evaluations on four aerial benchmarks have proven the effectiveness of HiFT. Real-world tests on the aerial platform have strongly validated its practicability with a real-time speed.
- IROS
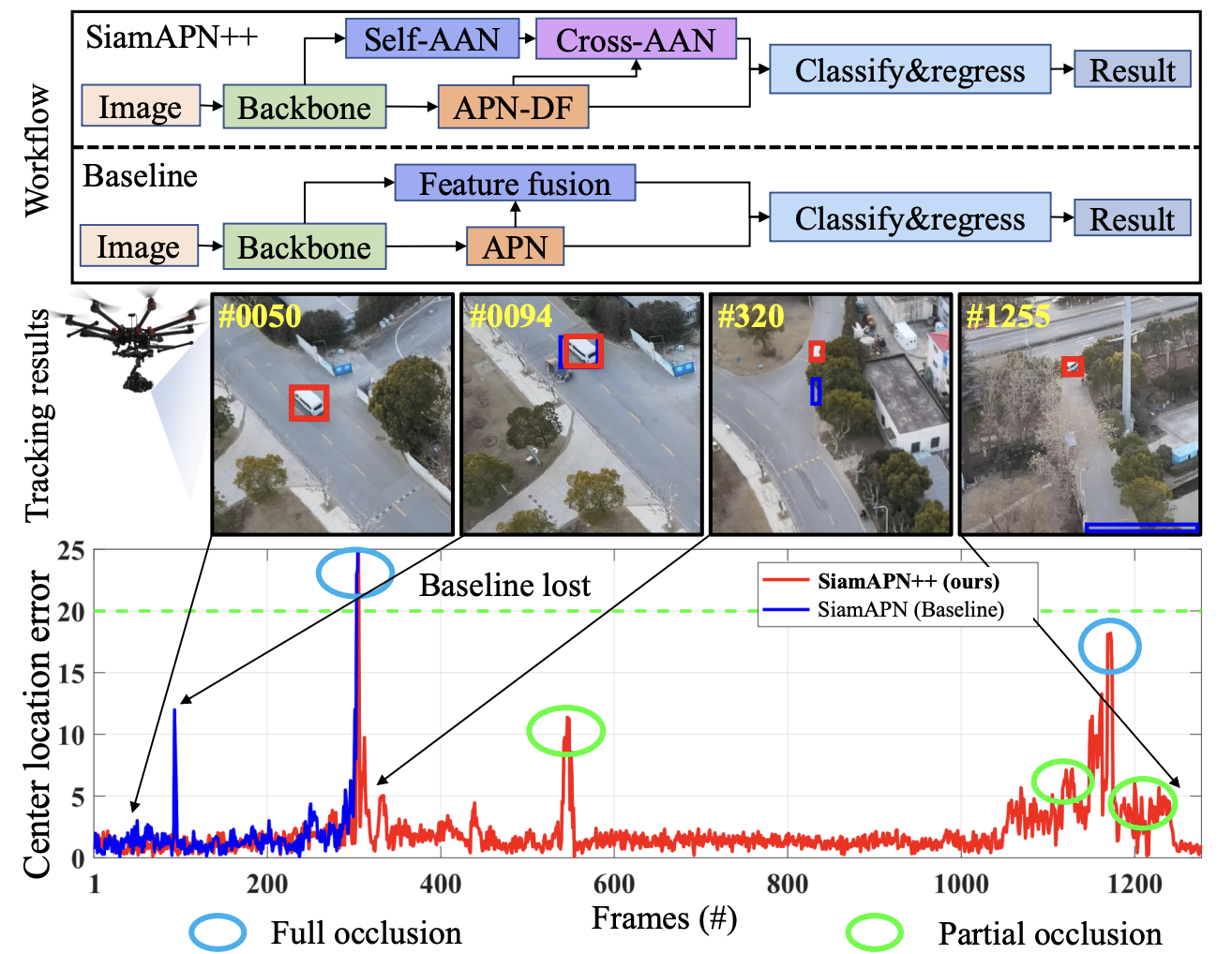 SiamAPN++: Siamese Attentional Aggregation Network for Real-Time UAV TrackingZiang Cao, Changhong Fu, Junjie Ye, and 2 more authorsIn IEEE/RSJ International Conference on Intelligent Robots and Systems, Jun 2021
SiamAPN++: Siamese Attentional Aggregation Network for Real-Time UAV TrackingZiang Cao, Changhong Fu, Junjie Ye, and 2 more authorsIn IEEE/RSJ International Conference on Intelligent Robots and Systems, Jun 2021Recently, the Siamese-based method has stood out from multitudinous tracking methods owing to its state-of-theart (SOTA) performance. Nevertheless, due to various special challenges in UAV tracking, e.g., severe occlusion and fast motion, most existing Siamese-based trackers hardly combine superior performance with high efficiency. To this concern, in this paper, a novel attentional Siamese tracker (SiamAPN++) is proposed for real-time UAV tracking. By virtue of the attention mechanism, we conduct a special attentional aggregation network (AAN) consisting of self-AAN and cross-AAN for raising the representation ability of features eventually. The former AAN aggregates and models the self-semantic interdependencies of the single feature map via spatial and channel dimensions. The latter aims to aggregate the crossinterdependencies of two different semantic features including the location information of anchors. In addition, the anchor proposal network based on dual features is proposed to raise its robustness of tracking objects with various scales. Experiments on two well-known authoritative benchmarks are conducted, where SiamAPN++ outperforms its baseline SiamAPN and other SOTA trackers. Besides, real-world tests onboard a typical embedded platform demonstrate that SiamAPN++ achieves promising tracking results with real-time speed.
- ICRA
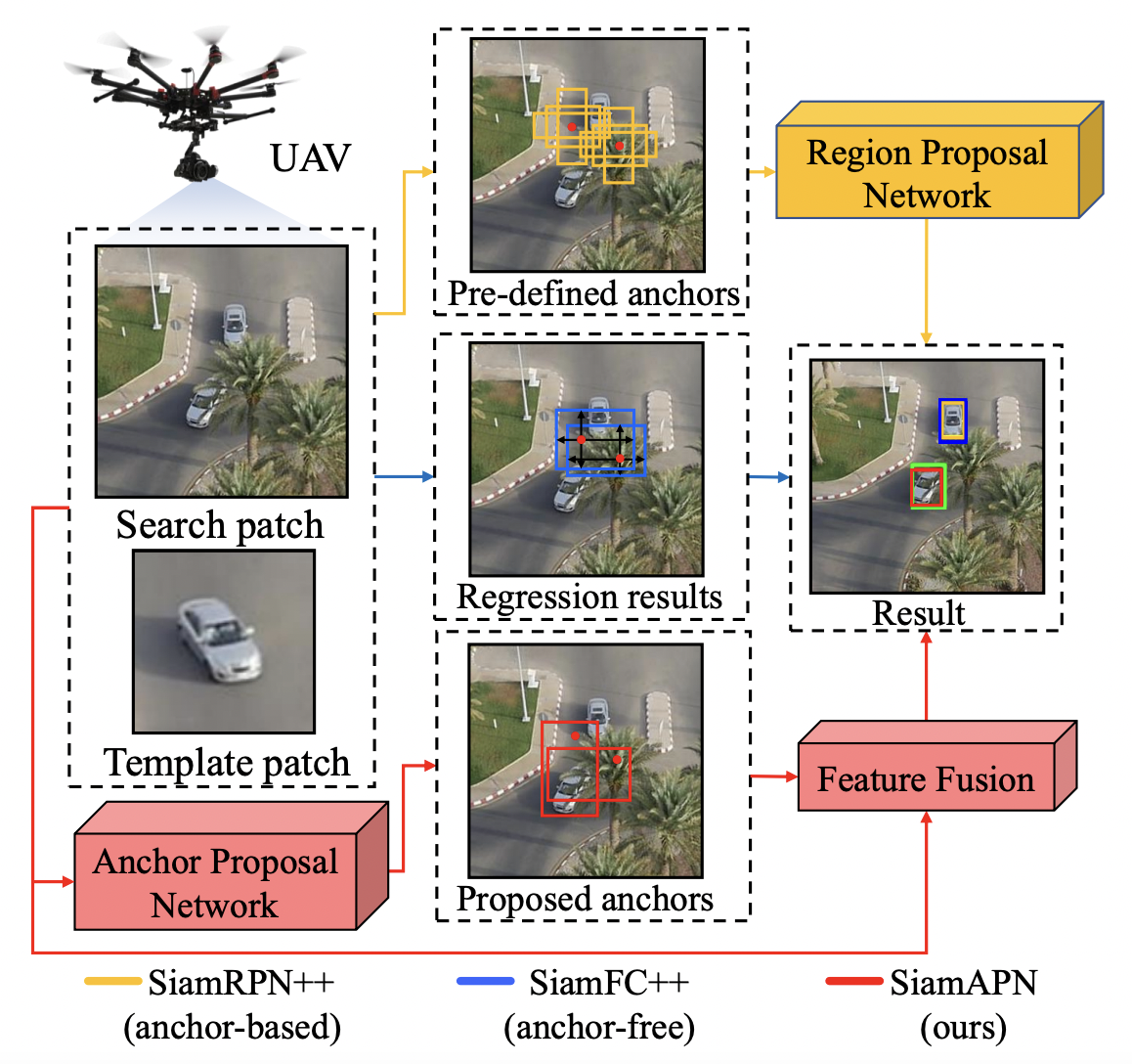 Siamese Anchor Proposal Network for High-Speed Aerial TrackingChanghong Fu, Ziang Cao, Yiming Li, and 2 more authorsIn IEEE International Conference on Robotics and Automation, Jun 2021
Siamese Anchor Proposal Network for High-Speed Aerial TrackingChanghong Fu, Ziang Cao, Yiming Li, and 2 more authorsIn IEEE International Conference on Robotics and Automation, Jun 2021In the domain of visual tracking, most deep learning-based trackers highlight the accuracy but casting aside efficiency. Therefore, their real-world deployment on mobile platforms like the unmanned aerial vehicle (UAV) is impeded. In this work, a novel two-stage Siamese network-based method is proposed for aerial tracking, \textiti.e., stage-1 for high-quality anchor proposal generation, stage-2 for refining the anchor proposal. Different from anchor-based methods with numerous pre-defined fixed-sized anchors, our no-prior method can 1) increase the robustness and generalization to different objects with various sizes, especially to small, occluded, and fast-moving objects, under complex scenarios in light of the adaptive anchor generation, 2) make calculation feasible due to the substantial decrease of anchor numbers. In addition, compared to anchor-free methods, our framework has better performance owing to refinement at stage-2. Comprehensive experiments on three benchmarks have proven the superior performance of our approach, with a speed of around 200 frames/s.





2020
- CVPR
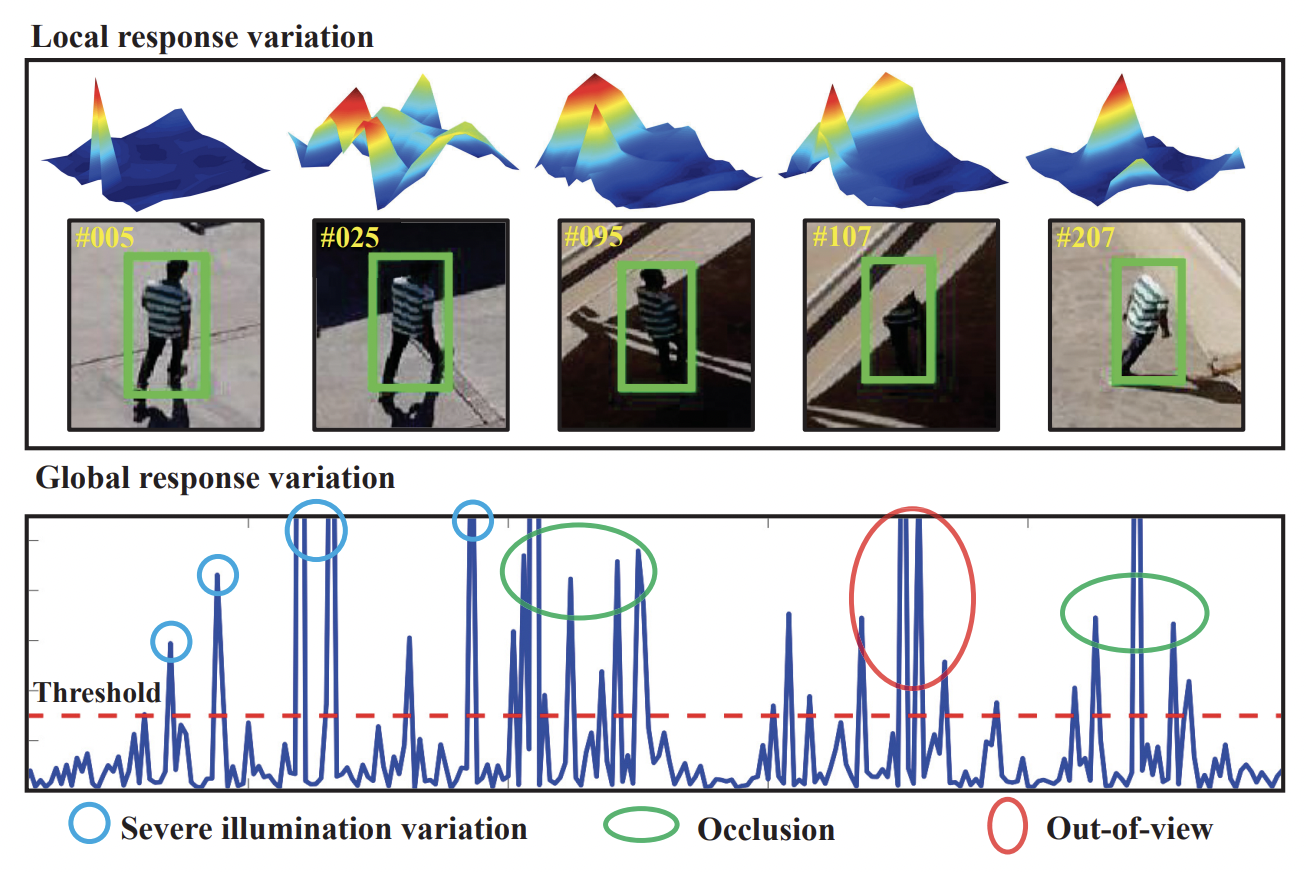 AutoTrack: Towards High-Performance Visual Tracking for UAV with Automatic Spatio-Temporal RegularizationYiming Li, Changhong Fu, Fangqiang Ding, and 2 more authorsIn IEEE conference on computer vision and pattern recognition, Jun 2020
AutoTrack: Towards High-Performance Visual Tracking for UAV with Automatic Spatio-Temporal RegularizationYiming Li, Changhong Fu, Fangqiang Ding, and 2 more authorsIn IEEE conference on computer vision and pattern recognition, Jun 2020Most existing trackers based on discriminative correlation filters (DCF) try to introduce predefined regularization term to improve the learning of target objects, e.g., by suppressing background learning or by restricting change rate of correlation filters. However, predefined parameters introduce much effort in tuning them and they still fail to adapt to new situations that the designer didn’t think of. In this work, a novel approach is proposed to online automatically and adaptively learn spatio-temporal regularization term. Spatially local response map variation is introduced as spatial regularization to make DCF focus on the learning of trust-worthy parts of the object, and global response map variation determines the updating rate of the filter. Extensive experiments on four UAV benchmarks, i.e., DTB70, UAVDT, UAV123@10fps and VisDrone-test-dev, have proven that our tracker performs favorably against the state-of-theart CPU- and GPU-based trackers, with average speed of 59.2 frames per second (FPS) running on a single CPU. Our tracker is additionally proposed to be applied to localize the moving camera. Considerable tests in the indoor practical scenarios have proven the effectiveness and versatility of our localization method.
- IROS
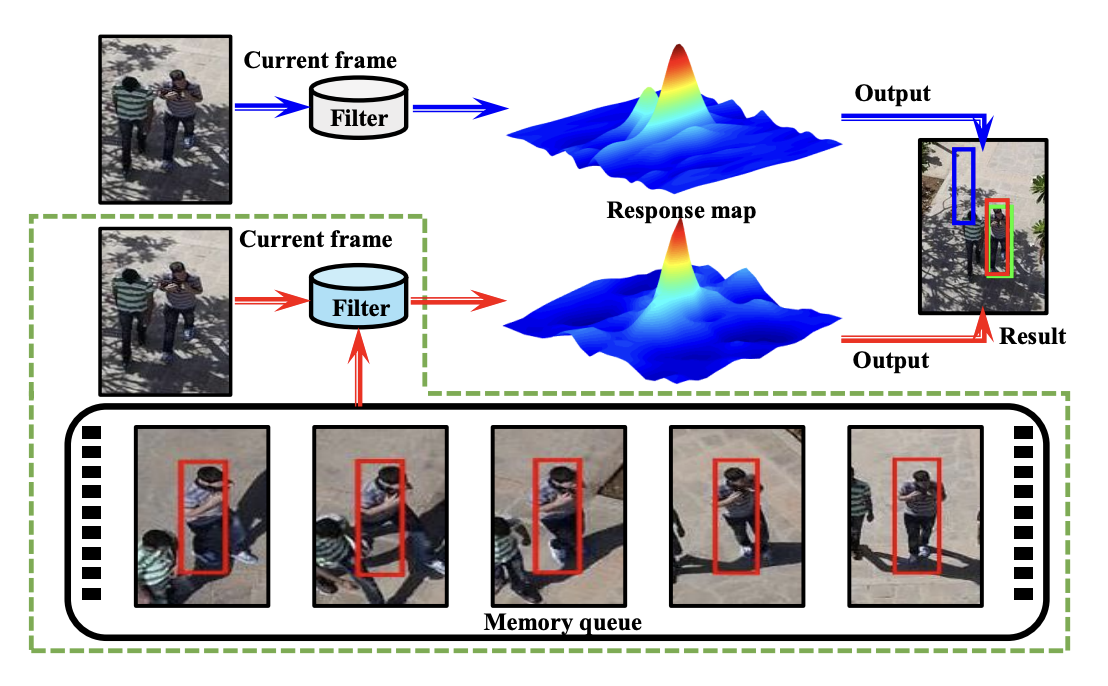 Augmented Memory for Correlation Filters in Real-Time UAV TrackingYiming Li, Changhong Fu, Fangqiang Ding, and 2 more authorsIn IEEE/RSJ International Conference on Intelligent Robots and Systems, Jun 2020
Augmented Memory for Correlation Filters in Real-Time UAV TrackingYiming Li, Changhong Fu, Fangqiang Ding, and 2 more authorsIn IEEE/RSJ International Conference on Intelligent Robots and Systems, Jun 2020The outstanding computational efficiency of discriminative correlation filter (DCF) fades away with various complicated improvements. Previous appearances are also gradually forgotten due to the exponential decay of historical views in traditional appearance updating scheme of DCF framework, reducing the model’s robustness. In this work, a novel tracker based on DCF framework is proposed to augment memory of previously appeared views while running at real-time speed. Several historical views and the current view are simultaneously introduced in training to allow the tracker to adapt to new appearances as well as memorize previous ones. A novel rapid compressed context learning is proposed to increase the discriminative ability of the filter efficiently. Substantial experiments on UAVDT and UAV123 datasets have validated that the proposed tracker performs competitively against other 26 top DCF and deep-based trackers with over 40fps on CPU.
- IROS
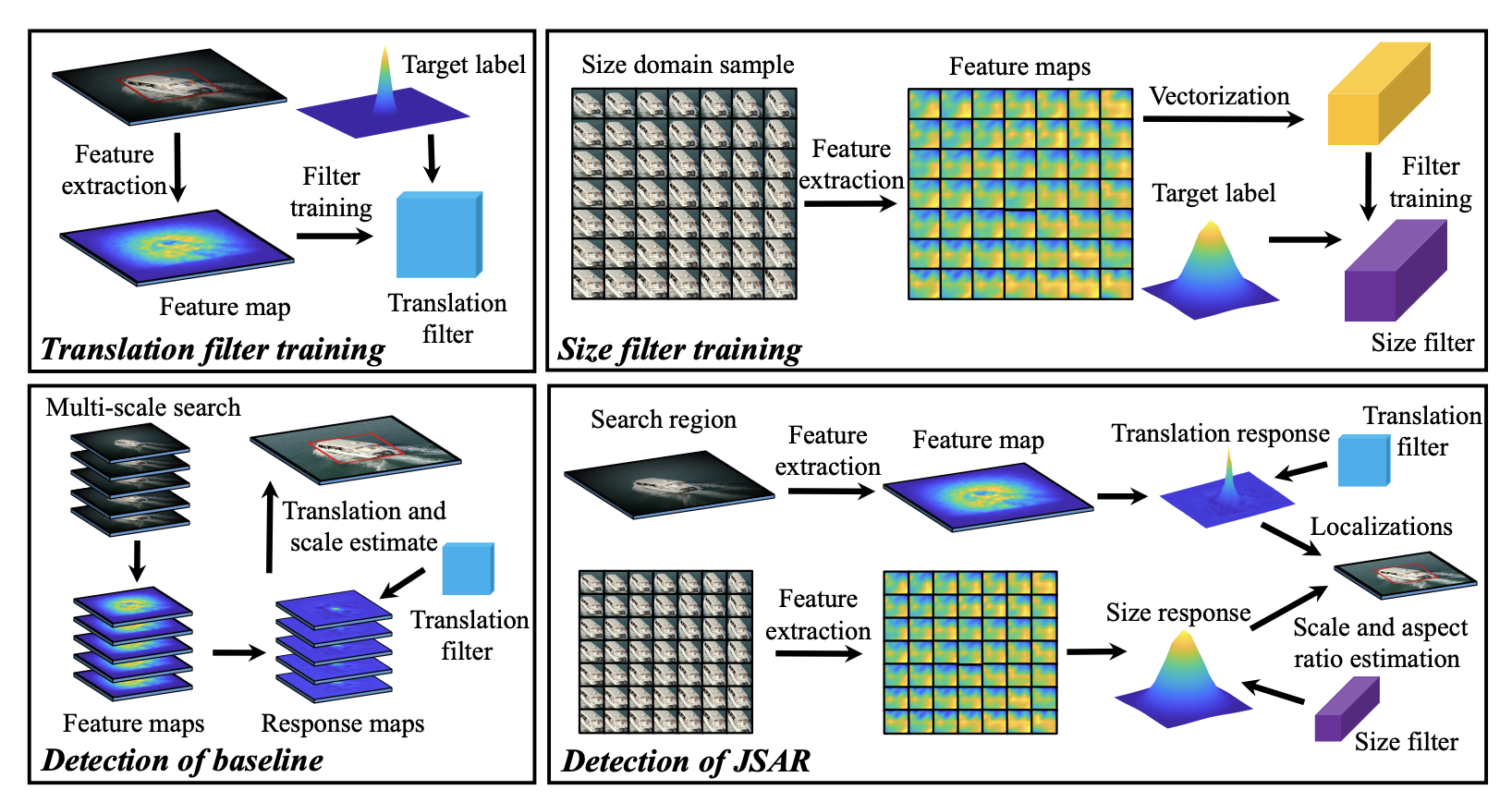 Automatic failure recovery and re-initialization for online UAV tracking with joint scale and aspect ratio optimizationFangqiang Ding, Changhong Fu, Yiming Li, and 2 more authorsIn IEEE/RSJ International Conference on Intelligent Robots and Systems, Jun 2020
Automatic failure recovery and re-initialization for online UAV tracking with joint scale and aspect ratio optimizationFangqiang Ding, Changhong Fu, Yiming Li, and 2 more authorsIn IEEE/RSJ International Conference on Intelligent Robots and Systems, Jun 2020Current unmanned aerial vehicle (UAV) visual tracking algorithms are primarily limited with respect to: (i) the kind of size variation they can deal with, (ii) the implementation speed which hardly meets the real-time requirement. In this work, a real-time UAV tracking algorithm with powerful size estimation ability is proposed. Specifically, the overall tracking task is allocated to two 2D filters: (i) translation filter for location prediction in the space domain, (ii) size filter for scale and aspect ratio optimization in the size domain. Besides, an efficient two-stage re-detection strategy is introduced for long-term UAV tracking tasks. Large-scale experiments on four UAV benchmarks demonstrate the superiority of the presented method which has computation feasibility on a low-cost CPU.
- ICRA
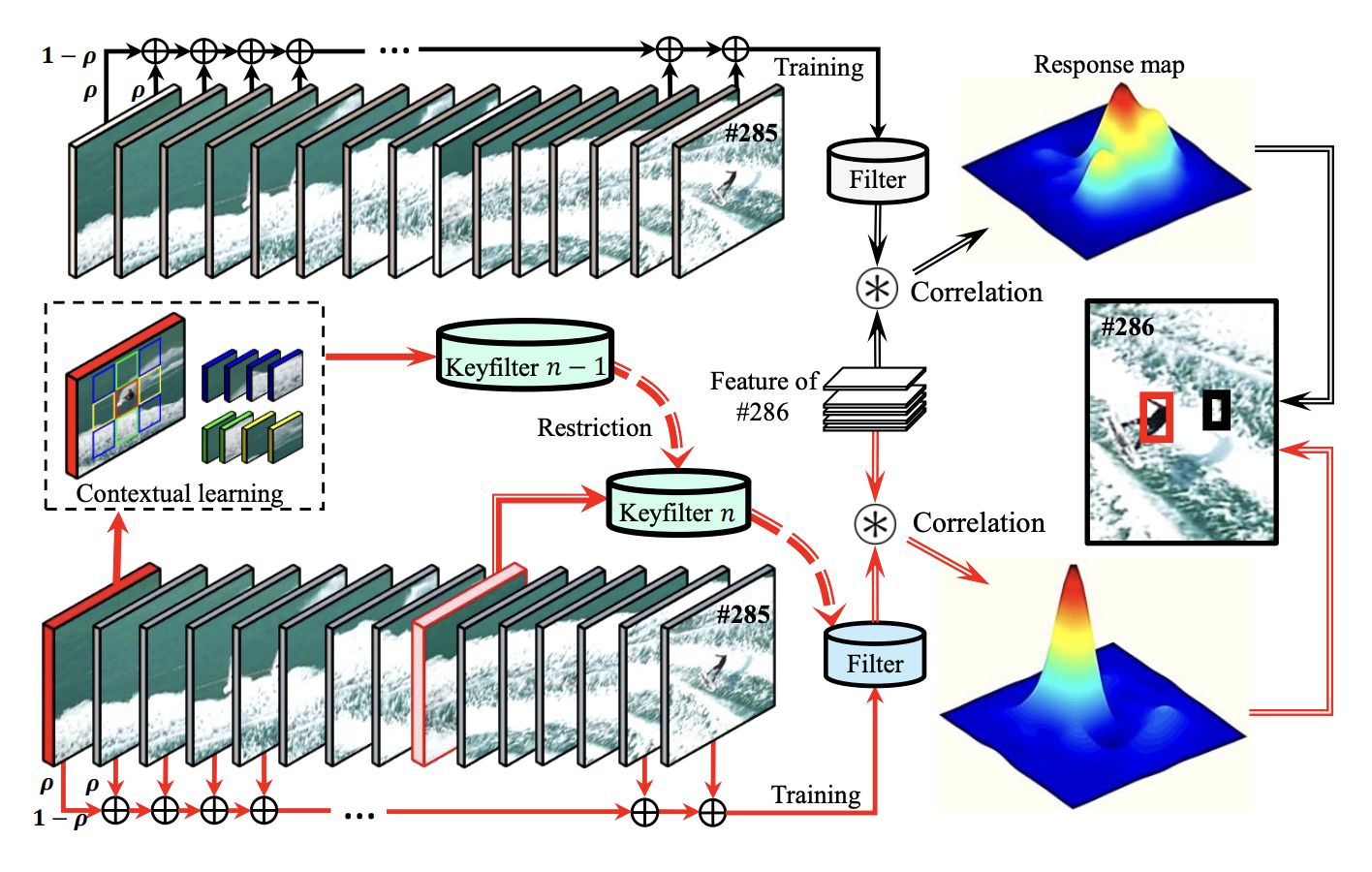 Keyfilter-Aware Real-Time UAV Object TrackingYiming Li, Changhong Fu, Ziyuan Huang, and 2 more authorsIn IEEE International Conference on Robotics and Automation, Jun 2020
Keyfilter-Aware Real-Time UAV Object TrackingYiming Li, Changhong Fu, Ziyuan Huang, and 2 more authorsIn IEEE International Conference on Robotics and Automation, Jun 2020Correlation filter-based tracking has been widely applied in unmanned aerial vehicle (UAV) with high efficiency. However, it has two imperfections, i.e., boundary effect and filter corruption. Several methods enlarging the search area can mitigate boundary effect, yet introducing undesired background distraction. Existing frame-by-frame context learning strategies for repressing background distraction nevertheless lower the tracking speed. Inspired by keyframe-based simultaneous localization and mapping, keyfilter is proposed in visual tracking for the first time, in order to handle the above issues efficiently and effectively. Keyfilters generated by periodically selected keyframes learn the context intermittently and are used to restrain the learning of filters, so that 1) context awareness can be transmitted to all the filters via keyfilter restriction, and 2) filter corruption can be repressed. Compared to the state-ofthe-art results, our tracker performs better on two challenging benchmarks, with enough speed for UAV real-time applications.




2019
- ICCV
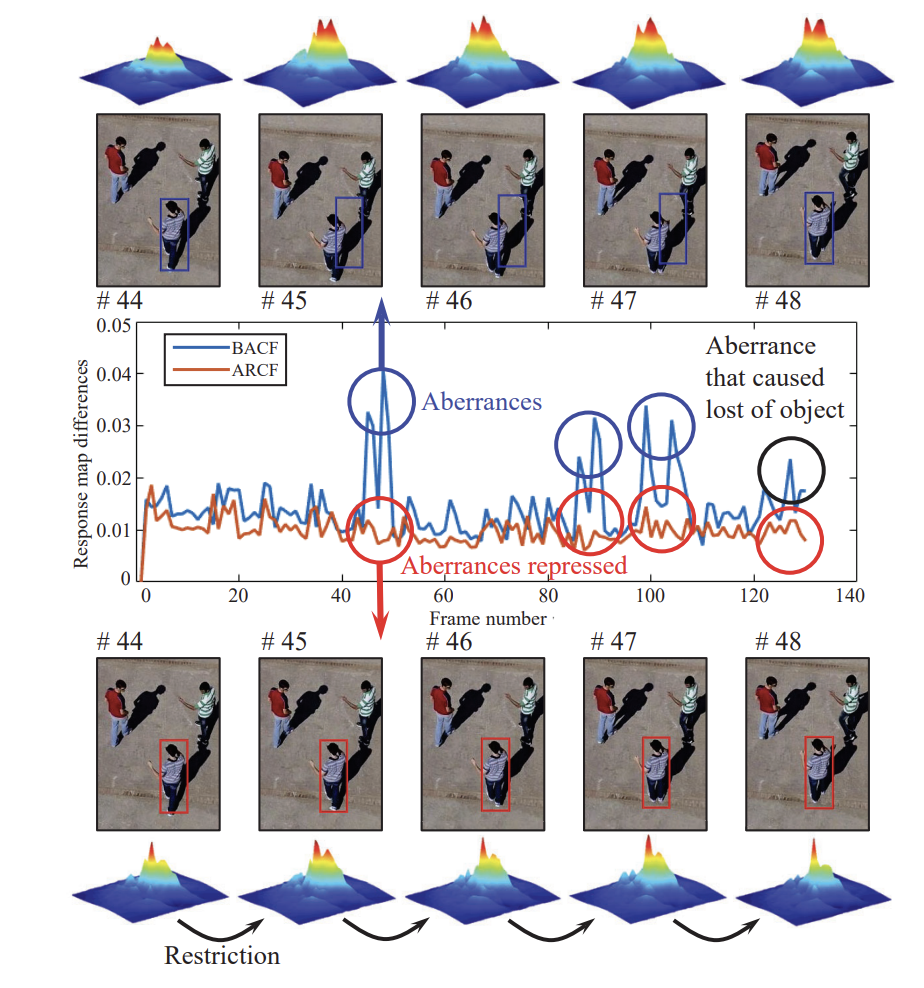 Learning Aberrance Repressed Correlation Filters for Real-Time UAV TrackingZiyuan Huang, Changhong Fu, Yiming Li, and 2 more authorsIn IEEE International Conference on Computer Vision, Jun 2019
Learning Aberrance Repressed Correlation Filters for Real-Time UAV TrackingZiyuan Huang, Changhong Fu, Yiming Li, and 2 more authorsIn IEEE International Conference on Computer Vision, Jun 2019Traditional framework of discriminative correlation filters (DCF) is often subject to undesired boundary effects. Several approaches to enlarge search regions have been already proposed in the past years to make up for this shortcoming. However, with excessive background information, more background noises are also introduced and the discriminative filter is prone to learn from the ambiance rather than the object. This situation, along with appearance changes of objects caused by full/partial occlusion, illumination variation, and other reasons has made it more likely to have aberrances in the detection process, which could substantially degrade the credibility of its result. Therefore, in this work, a novel approach to repress the aberrances happening during the detection process is proposed, i.e., aberrance repressed correlation filter (ARCF). By enforcing restriction to the rate of alteration in response maps generated in the detection phase, the ARCF tracker can evidently suppress aberrances and is thus more robust and accurate to track objects. Considerable experiments are conducted on different UAV datasets to perform object tracking from an aerial view, i.e., UAV123, UAVDT, and DTB70, with 243 challenging image sequences containing over 90K frames to verify the performance of the ARCF tracker and it has proven itself to have outperformed other 20 state-of-the-art trackers based on DCF and deep-based frameworks with sufficient speed for real-time applications.
