


About Me
Hello! I am a research scientist at NVIDIA, working on physical AI and autonomous vehicles with Marco Pavone at Stanford University. I obtained my PhD degree from New York University (NYU) in 2025, working on robot perception with Chen Feng. I am also fortunate to collaborate with Saining Xie on visual-spatial intelligence. During my PhD, I did three internships at NVIDIA, working on autonomous perception and neural simulation with Anima Anandkumar (Caltech), Sanja Fidler (UofT), Jose M. Alvarez, Zhiding Yu, Chaowei Xiao (JHU), Zan Gojcjc, and Yue Wang (USC). I also spent some time at Tsinghua IIIS with Hang Zhao and Shanghai Jiao Tong University (SJTU) with Siheng Chen.
My research has been cited nearly 4,000 times (as of Nov 2025), and I am honored to be a recipient of the NVIDIA Fellowship (2024-2025), NYU Dean's PhD Fellowship, and NYU Outstanding Dissertation Awards (Finalist).
🎓 Recruiting: Looking for postdocs, PhD students, undergraduates, interns, and visiting scholars to join my lab. Welcome to reach out!
⏳ Deadline: International PhD applications for Fall 2026 are due by January 15, 2026. Urgently seeking qualified candidates!
Research Lab - Spatial Intelligence
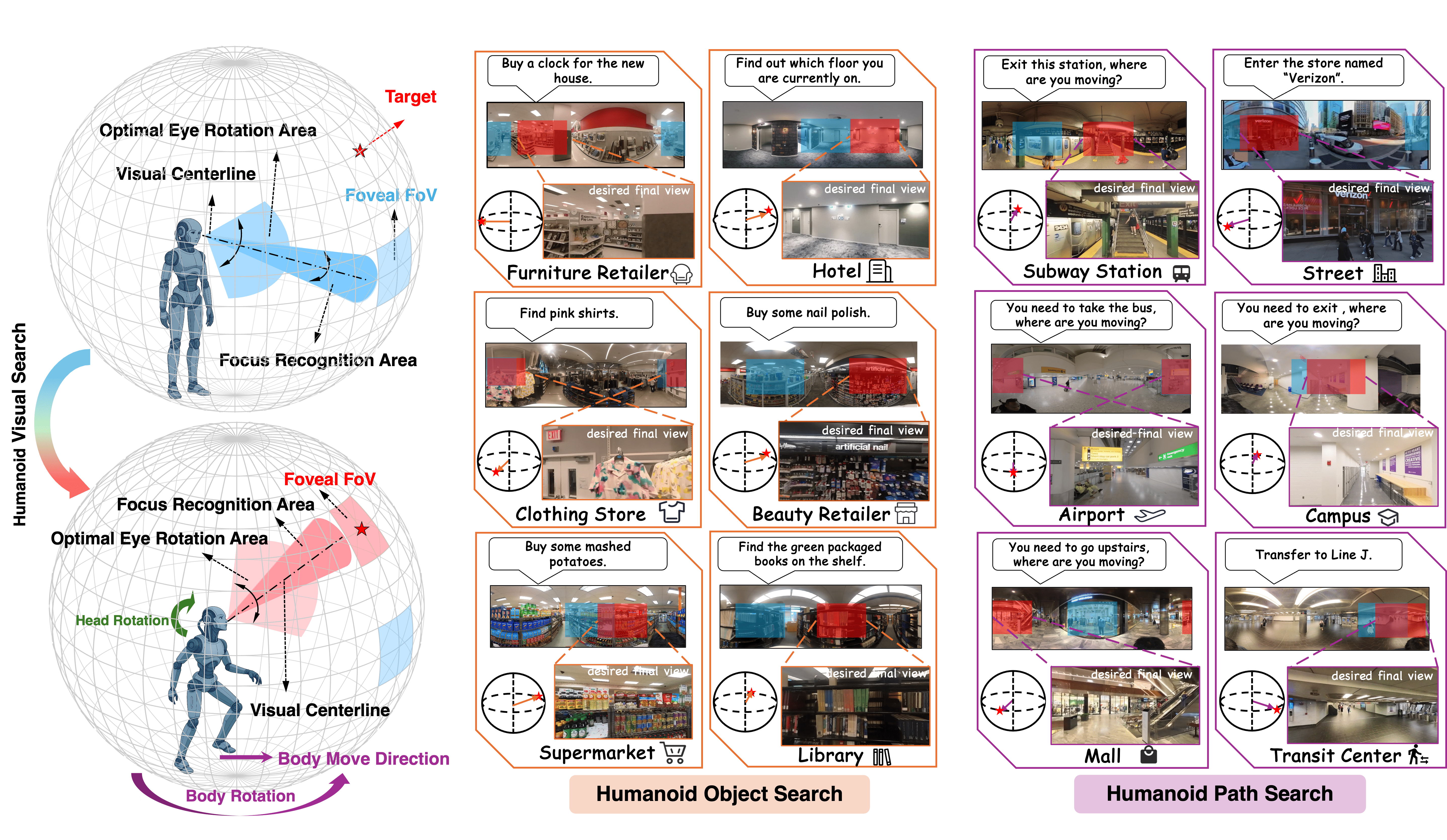
Our mission is to scale AI across space, time, and embodiments to address real-world challenges. Towards this end, we are pushing the frontiers of spatial intelligence through the convergence of vision, learning, and robotics. Our research agenda centers on three thrusts:🧠 Research Thrust 1 - Spatial Cognition: How can embodied agents perceive, represent, and reason about space and time like humans do?
Sensing and Perception, Spatial Representation, Spatial Reasoning, Spatial Memory, Spatial World Model, Cognitive Mapping, Mental Manipulation
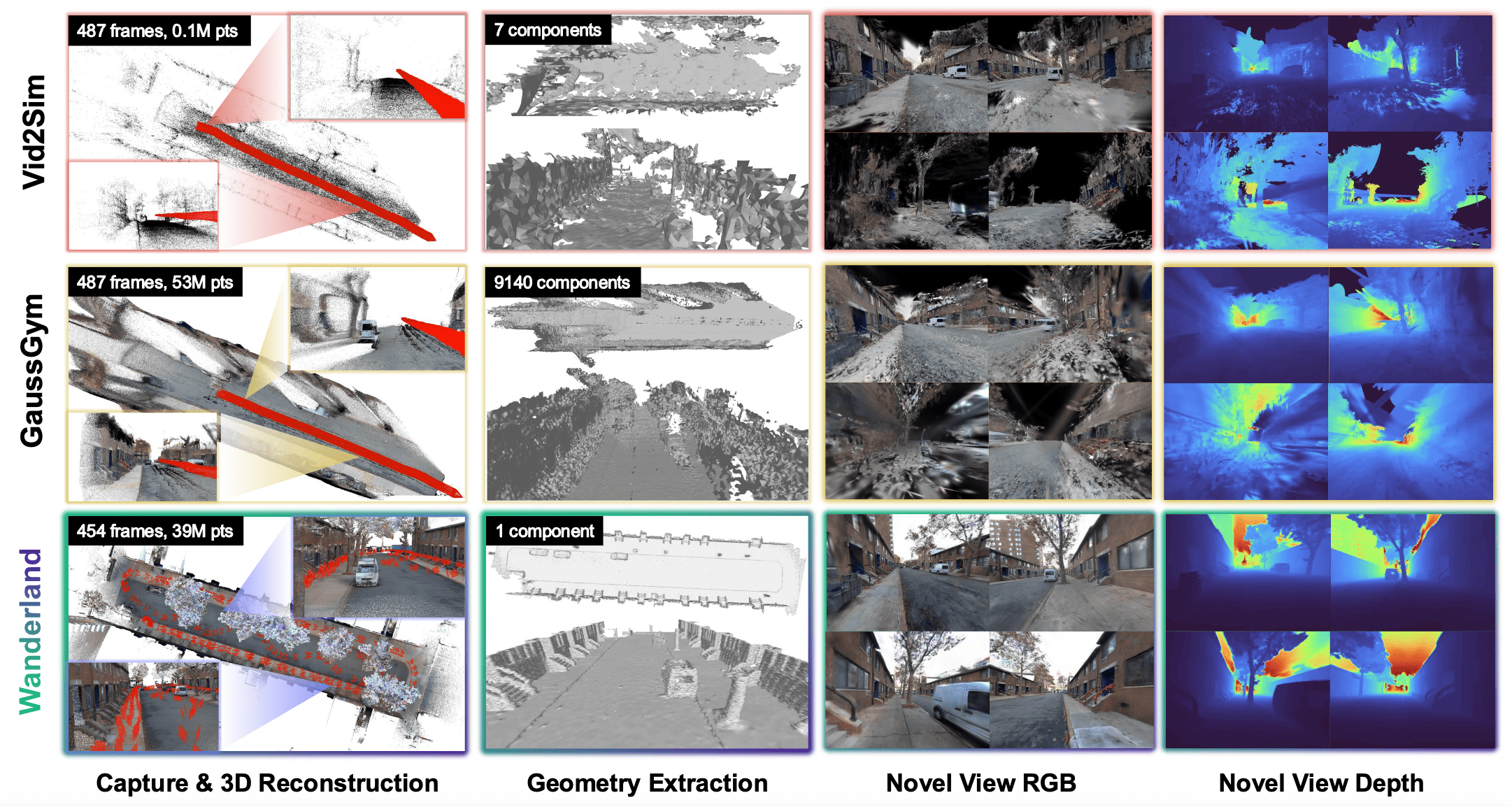
🌏 Research Thrust 2 - Spatial Computing: How to create realistic digital twins from multimodal sensory streams without human supervision?
3D Reconstruction, Neural Radiance Fields, Gaussian Splatting, Physics-based Simulation, Generative Modeling, Real2Sim2Real, Edge-Computing
🦾 Research Thrust 3 - Spatial Robotics: How can we ground cognitive intelligence in real-world robots across different morphologies?
Autonomous Navigation, Humanoid Robotics, Multi-Robot System, Field Robotics, Bio-Inspired Robotics, Robotic Design and Its Automation
💡 We believe the above three thrusts are deeply synergistic: cognitive models trained in simulation are grounded in physical robots, whose real-world experiences in turn benefit both the cognitive models and digital worlds. Our long-term vision is to build a self-sustaining, self-evolving spatial AI ecosystem where machines autonomously perceive, reason about, and transform the physical world—enabling AI Designs AI, Robots Build Robots through the seamless convergence of embodied cognition, digital universe, and physical embodiments.
💪 Towards this long-term vision, we are currently pushing the following research directions:
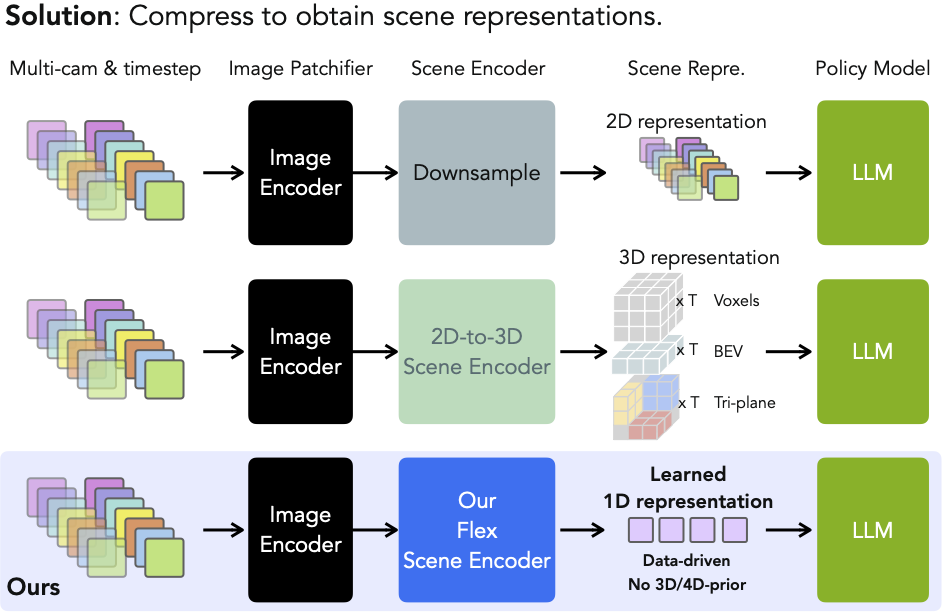
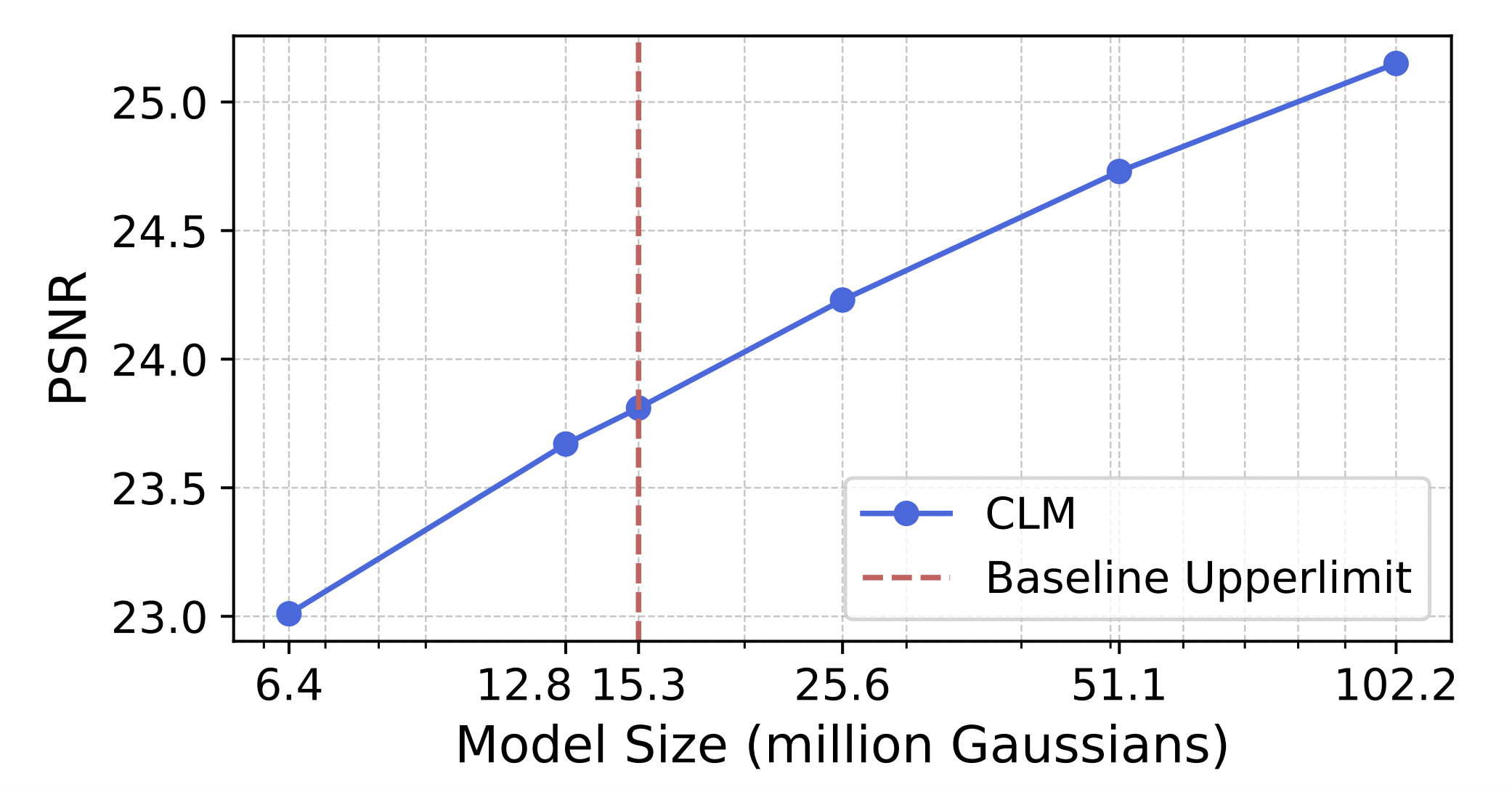
- Prototyping spatially-grounded foundation models
- Exploring human-like efficient spatial representations
- Building open-world embodied AI simulators
- Grounding visual-spatial intelligence in humanoid robots
- Constructing large-scale datasets and benchmarks to broaden the practical applications of spatial AI
- Designing specialized physical embodiments to diversify problem domains of spatial AI
📣 To advance our mission, we are building an interdisciplinary team and welcome researchers with diverse expertise, including but not limited to: (1) AI Computing (e.g., MLLMs, UMMs, VFMs, world model, generative model), (2) 3D Vision (e.g., 3DGS, NeRF, SLAM), and (3) Robotics (e.g., sim2real, humanoid robotics, field robotics, robotic design). Please send me an email, and I will get back to you if there is a good fit!
Selected Publications
(* indicate equal contribution/advising)
For full publication list, please refer to my
 Google Scholar page.
Google Scholar page.






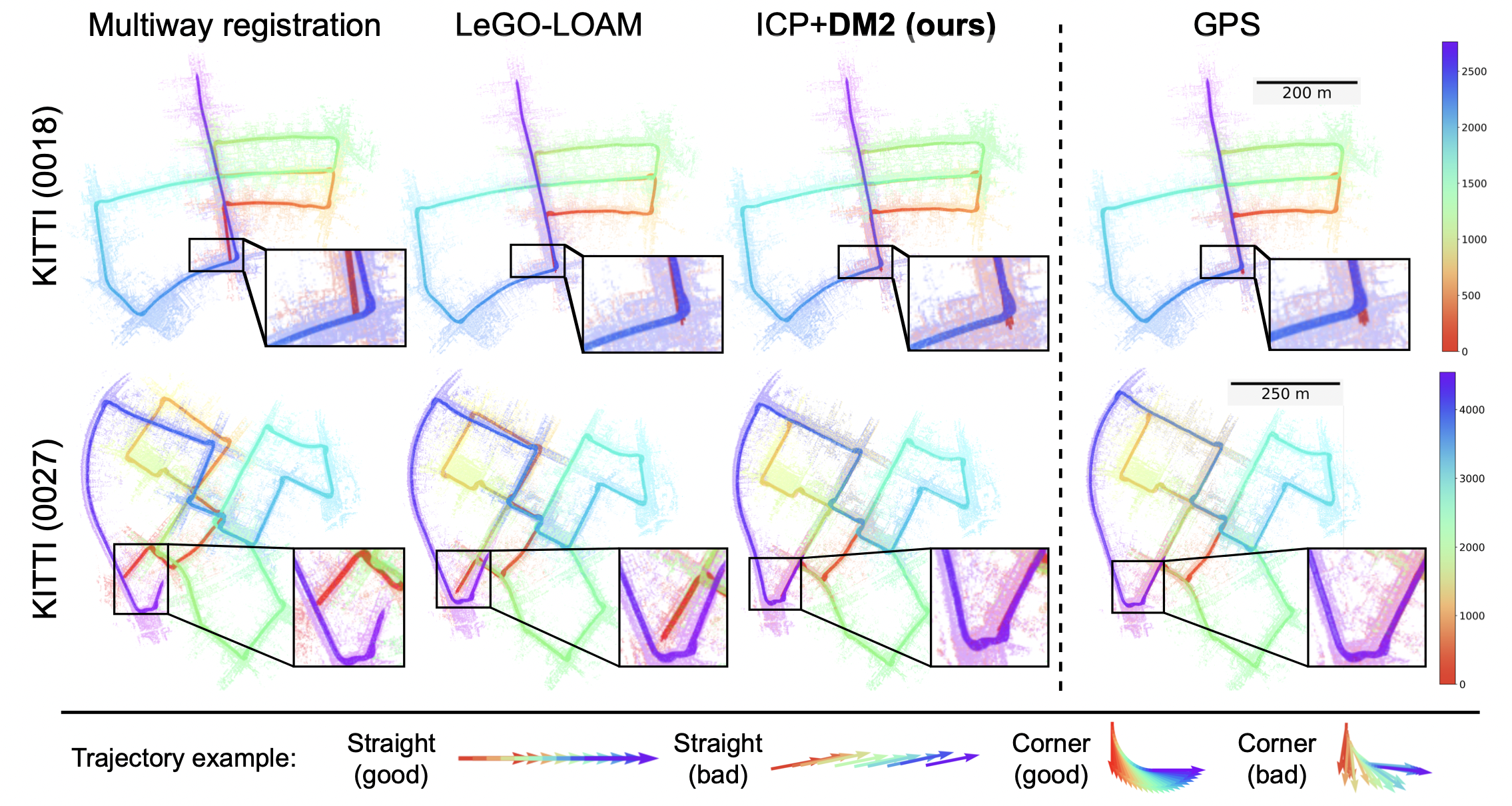
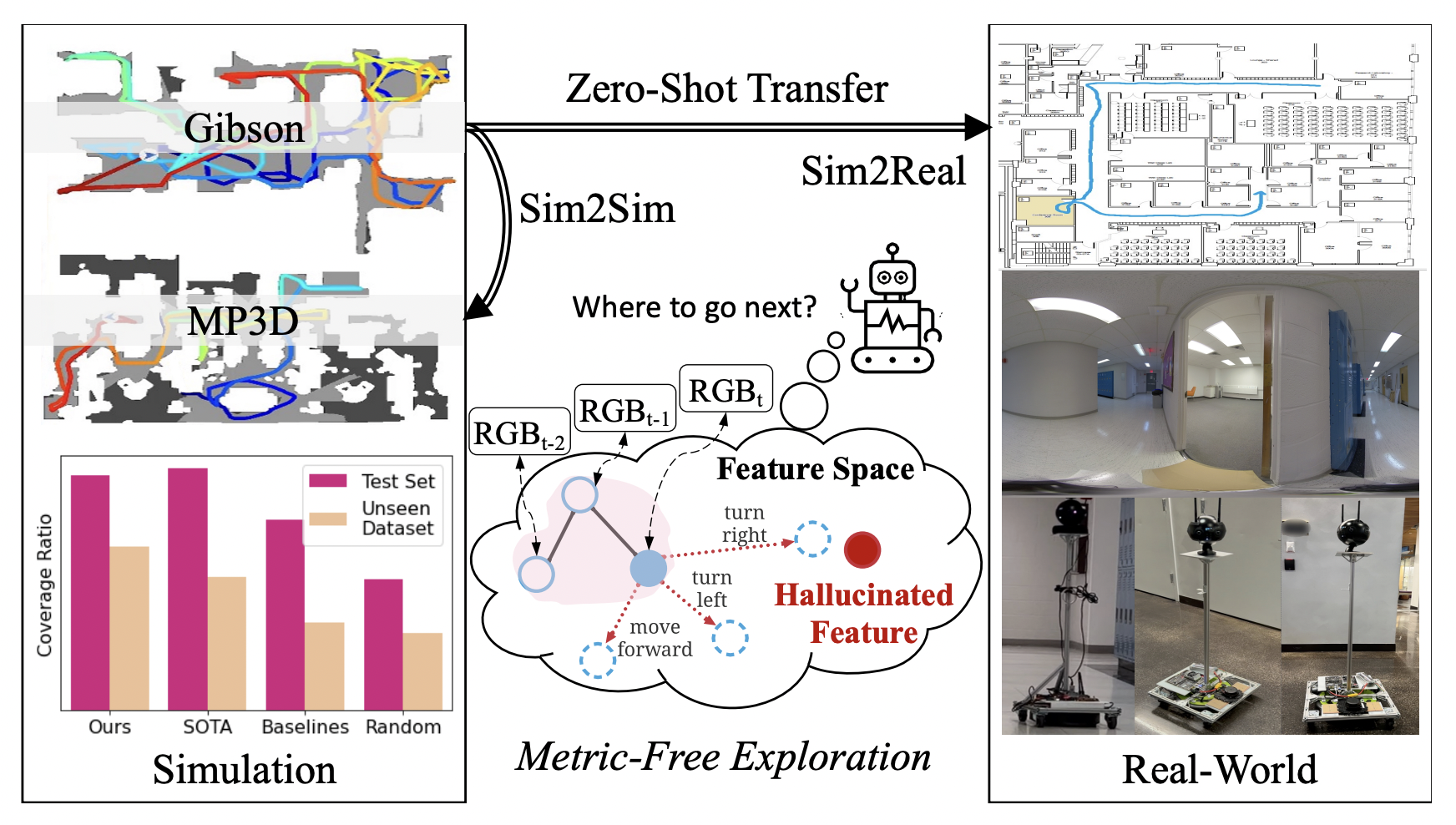
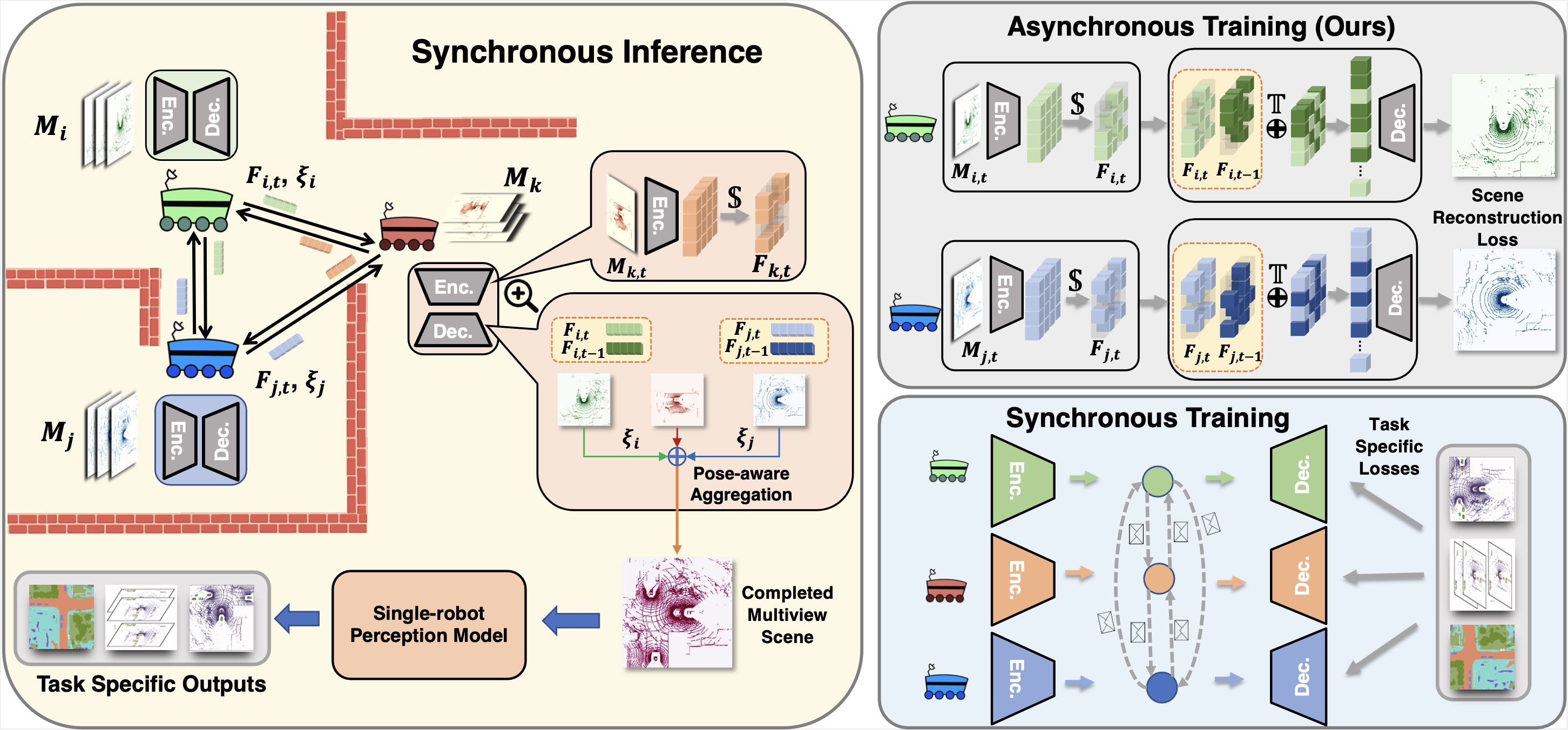

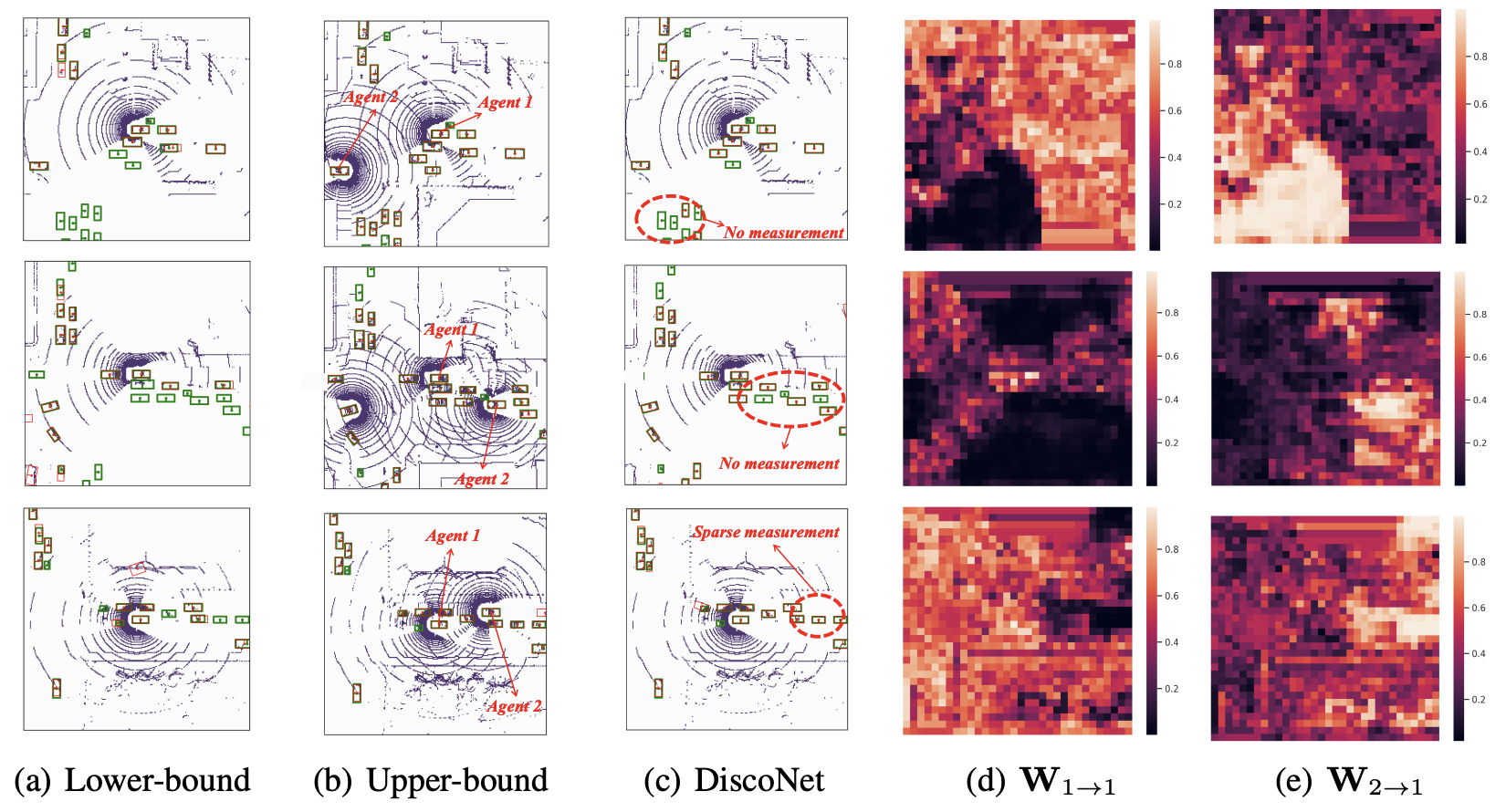
🌍 Visitor Statistics

Last updated: Nov 26, 2025